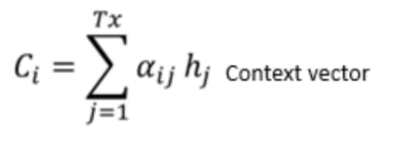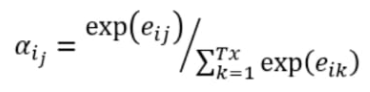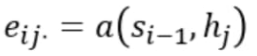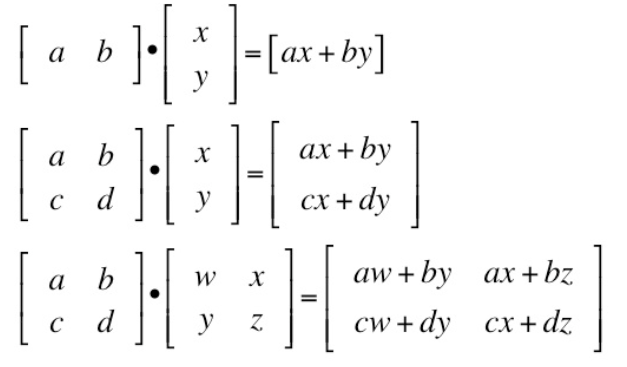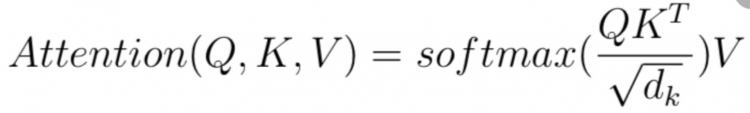Before going further, we just need to know what is word embedding. The idea is just that we need words being just a list of characters are of letters. We want a vector out of it, so the idea is that computers and algorithms are way more compatible with vectors.
Only numbers don’t make any sense, so we need vectors representations of words to make it the most powerful possible so now we have a connection between words and get meaning out of it.
Word Embedding
If we say we have a vocabulary of 10,000 words, then each word will be a vector of that size. We will have unique representations for each of our 10,000 words but there is absolutely no relation between them. There is no meaning, no mathematical relation between the words.
So instead of having 10,000 vectors, we would like to have a smaller size like example 70, now it has less liberty and that forces our system to create a relationship link.
For example, we have a vector dog, instead of being a vector of size 10,000 with all the zeros but now it will be the size of 64 and it won’t be binary anymore. It will take numbers from 0 to 1.
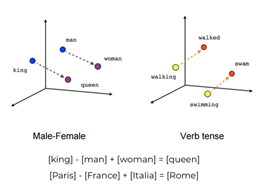
Now we have meaning between the vector so sending vectors means sending meaning in our embedded space. Let’s see an example to make it clear, here as we see if
king – man + woman = queen
In the above picture as we see the words having similar meanings are close to each other in embedded space. As we see in the example data is close to information as both carry similar information.
Word embedding mathematical works
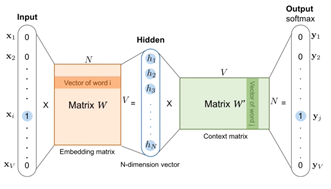
We will take the input vector as a one-hot encoding vector. The product of input and embedding matrix and have an embedding vector.
How to train the model to have semantic relations between input and output vectors?
We will use a skip grant model where basically for an input word, we will pick several other words, which we called context and we want them to appear in the output vectors.
To create an output we need to have a large stack of sentences we will split the vectors. for each word, we will take two previous words and two next words as context.
Let’s take an example “In spite of everything. I still believe people are good at heart”. Word good produces pairs like (“good”, “are”), (“good”, “really”), (“good”, “at”), (“good”, “heart”) as a context.
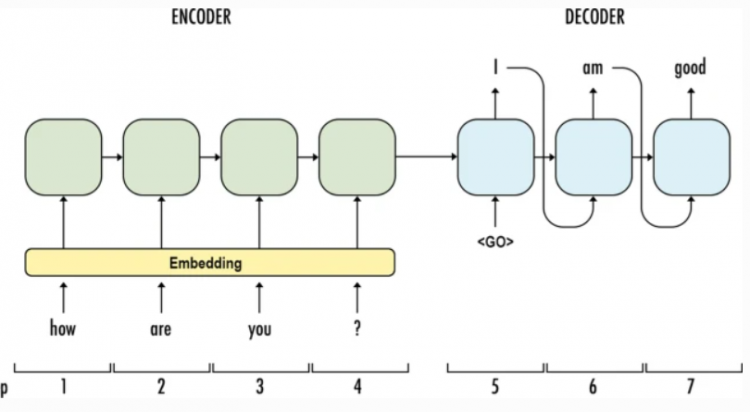
The encoder will summarize all the information that we want to use from the input sentences and the decoder will use it as inputs to create an output of the encoder in order to create the right output. The old method to do this with the help of Recurrent Neural Network RNN.
Steps to perform RNN
First we will embed the words into vectors so they can be used more efficiently by algorithms.
Each new state of the encoder is computed from the previous one and next word.
The final stage of encoder passes the information to start decoding that we want to have from input sequence.
Now we will apply decoders which uses the previous hidden state and output word to compute a new hidden state or word; in easy terms it’s like unrolling the information which we get from the encoder.
Limitations
As we are not passing the whole sentence but only passing the words the essence of the sentence is not there or we will certainly loose the information from the begining of the sentence to each words we add.
We could also loose the infomation which we loose at the encoding phase. To address this issue what we do is add attention mechanism.
Attention Mechanism in RNN
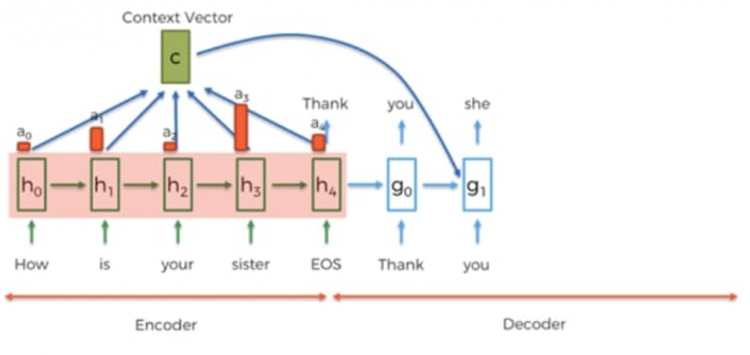
During the decoding phase, we add a new input to our cells in the RNN and then call the context vector and that’s vector will convey the information about the whole input sequence.
Let’s see an example suppose we are in the decoding phase at 2nd last word and we predicted the word she. We have a hidden state g1 and in parallel, we will compute the g2 by using a g1 hidden state and previous predicted word she and get the new word is.
But here, we added a new input, which is vector C that is created by hidden states of the encoder.
Now comes the question of how to send those hidden states? It’s represented by the coefficient, a zero and one, and so on. Hidden states, so how our current decoding phases is related to each of the encoding phases. So just having declared the subject is related to each of those hidden states and naturally. So that’s how the attention mechanism works in the RNN.
The mathematical equation for attention mechanism
We use a softmax function in order to create weights for a weight. So the coefficients of being the similarity, for instance, between the state of our decoder and the hidden state of our encoder being those coefficients. Now we just need them to compute the alpha order to keep the relation between E.
There is a direct proportion to the coefficients and alpha as one increases others one too increase. But as we are using softmax, the sum will be equal to one and each number will be between 0 and 1.
To see the similarity between the words we use a similarity function between the current hidden state and all of the hidden states of the encoder. As now we have similarity weights, we just need to apply a softmax function in order to have a real weight that we can use for weighted sums.
And we apply those weights to all the hidden states of the encoder to finally have a vector that is mostly made of the hidden states from the encoder that are related to our current state in the coding phase.
Transformers – Intutions
We saw how the attention mechanism works in RNN. There are some disadvantages too. The RNN is sequential processing so, it doesn’t have global behaviors concerning the input sequence and so we lose the important information along the coding process.
The fact that the large hidden state of the encoder, which is the final output of the encoder, has not seen the beginning of the sentences for quite a long time could make a disturbance in the model.
So for very long sentences or very long sequences, we lose a lot of information and that’s a huge demerit. Attention mechanism added the global behaviors to the coding phase, but the audience still has the weakness of not being global enough. Google introduced a paper called Attention which is most helpful here.
In the above picture, we have two main blocks; one on the left is an encoder and another one on right is the decoder. The change in the architecture is that our input for the encoder will be the whole sentences, so we don’t feed the input of the encoder single words.
The second main change is that the output of our decoders is a new input as we did before but now with the whole sentences. Here is the key we use inputs for our decoders is the one that we already had the previous iterations in the decoders. Additionally, the new words that we will predict at the end of this sequence
Summarizing the working
For example, when you have two sequences, it just composes the first sentence to how each element of the first sentence is related to the elements of the second sentence. Here, we use the same sentences three times, and actually that they call self-attention which is the key of the encoder in the transformer.
Before RNN we use standard neural networks, we have the information of the beginning of the sentences and then we add new words. We do the computation and we get the new information about the sentences.
But now we have whole sentences and we will see how each word of its sentences is related to the other words of the sentences then we will recompose these sentences according to that.
Let’s take an example “The animals didn’t cross the street because it was too tired”, here when we apply the attention mechanism it computes how each word of the sentence is related to the others. Here the word ‘it’ refers to animals that was too tired. When we see the output then the word it will produce a combination of strong words related to the sentence.
The goal of applying the self-protection mechanism is to combine everything so that each element doesn’t only represent the words but also represents the relation between the different words of sequences. This is the whole process of how self-attention works.
Mixing the information from the encoder according to how each element is related to this sequence from the decoder. We will see this in detail in the attention mechanism.
Attention in Tranformer
Till now we saw a general idea about transformers which is the base of the bert model.
Let’s say we have two sentences that can be equal in the case of self-attention, B will be the context and A will be the sequence that we want to really work with. This is the sequence that conveys the information that we want to rearrange in a certain way.
This can depend on the use case as supposing we are working with a translator there are changes that one sentence in is English another one is in French and another one in any other language. Now we want to apply the attention mechanism and check how sentence A is related to sentence B.
So we want to arrange the information according to how each element of it is related to the elements from B. How to do it?
Before doing the attention mechanism we have a beginning of sequence A and context B that will let us know how we manipulate N and outputs. We have a new sequence where each element will be a mix of elements from A sentence that are related to the B elements and not B words.
So generally speaking B tells us how we will combine elments from A or in the case of the self attention and A tells us how we recobine a sentnece.
Dot product
The dot product is very useful to capture the similarities between two words. The way of computing the similarities focuses on the directions of the vectors.
If the product = 1, there will be No correlation
If the product = 0, there will be collated in an opposite manner if the other product is -ve one.
See in the below image the word joy and despair are the opposite words so they are in the opposite direction. so the dot product between joy and despair will be -1 and we see the word tree is not particularly related to joy and despair that’s why it’s perpendicular.
Now we see how the Dot product works, so we will be doing dot product of the A and B sentences. The below attached image explanation.
Exmaple 1: Here, as we see left vector is horizontal and the right vector is vertical, and do the dot product.
Exmaple 2: Here, as we see left is a matrix and the right vector is vertical, and doing the dot product we get whole matrix.
Exmaple 3: Here, as we see left and right both are matrix, while doing dot product we get a matrix. This type of calculation is done when we want to compute many products at a time.
How to do scale dot product?
Let’s understand the formula first then moves to architecture.
We have two sequences A and B which are K and V and Q will be the context.
Steps to do
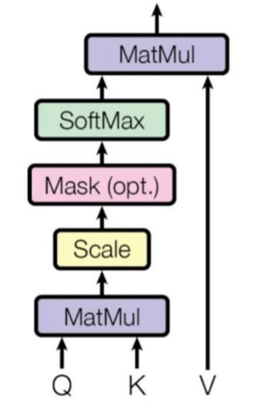
Product of two Q and A where Q which is the context of the sentences with the A which is sequence and after the embedding, each sentence being a matrix, we get all the products that we wanted.
Now we will do small scale it’s just something we need to do to improve the model and it stabilizes the whole process.
The next step is to apply softmax; softmax takes input as a vector and gives a vector with the same dimensions but each element will be between 0 and 1. The most important thing is we keep the relations between each element of the initial vectors.
So now if element two was lower, then element three will be the same after the softmax.
The second point of softmax is we just keep half each element is greater or lower than the others.
The third point is that the sum of all the elements from the output of such max should be equal to 1, the reason fits the weights in mathematics.
This shows that no information get out of hands just because the sum of quals 1. So this softmax is neceesary in order to get valid weights
The below picture shows the A and B sentences similarity between the two words. As the range of black color increases the similarity between the words decreases, the whiter the color is, the more important the similarity between the words.
As we saw how the self-attention mechanism works.
So in this case, C and U would be equal to K and V, so the initial sentence and the context sentence are the same, which means that we will compose the sentence according to how each word of this sentence is related to the other words of this other sentences.
We repeat this process several times in the paper they say we do that eight times in order to make sure that we get the most out of this recomposition of the information. So in the training, we will have a pair of text or a pair of sentences.
Look ahead mask
During training, we feed a whole output sentence to the decoder, but to predict the word N, he must not look at the word N. Let’s change the attention matrix. We will change the self-protection mechanism when we compose the sentences there we will use the elements from the sentence, which are actually the starting token and the first AI minus one word.
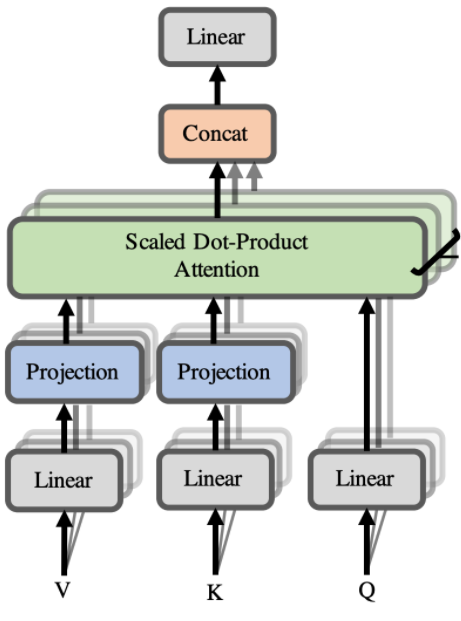
Multi-head attention layer
Let’s understand how the mechanism works, scale dot product is not directly applied to the sentences. They first completed linear projects and after that they do concatenations. So instead of applying skills that predict attention to the whole sentences, they split each factor from the sentences.
Let’s take an example like each word after embedding has 12 dimensions, we will split into four sequences having three dimensions then we compute the scale that attention and can get the result in order to get back. Now attention mechanism can focus on these 3 dimensions so that the information is not faded into the 12 initial dimensions of the embedding.
Splitting the space into spaces allows the attention mechanism to attend to more information and to be able to get more relations between the elements of a sequence.
Mathematically
One big linear function is applied first and then a splitting allows each subspace to compose with the full original vector. Splitting and then applying a linear function restricts the possibilities.
Architecture
Bert is just a stack of simple encoder layers of the transformer which allows it to encode the sentences, encodes a language in the most effective way. So be composing information between every word of the sentence according to the relations between each other.
In the paper, Google talks about two different models that the choice that they implemented, the first one that they called Bert Base, and the second one which is bigger called Bert Large.
Hyperparameters used are:
L– Number of encoder layers
H – Hidden size
A – Number of self-attention heads
The two models configuration
Bert base: L=12, H=768, A=12, parameters: 110M
Bert large: L=24, H=1024, A=16, parameters: 340M
The large module uses twice as many layers compares to the base model.
Bert’s input flexibility
We want our input to go in 2 ways; in single sentences and pairs of sentences. So instead of having one vector per word, we would like to have a vector that could be directly used for classification, that can summarize the whole sentences.
We want to have easy access to a classification tool: [CLS] + Sent A + [SEP] + Sent B
CLS: classification token
SEP: separation token between 2 sentences
How to give input to the best? We will convert the sentences into tokenization; here each token will be related to a number so our computer can understand easily. We can deal with the new words by combining known words and it will try to process the biggest word possible in order to decompose an unknown word.
If the word is just a bunch of nonsense, random letters, or numbers it will split the word into random letters.
In the above code, the tokenization is done by splitting the words as we see the last word transformer; it’s not a common word that’s why the tokenizer splits the word into two words transform and er.
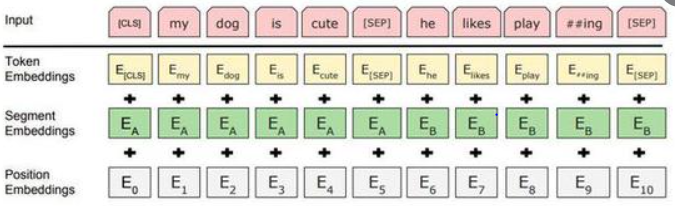
As we see in the above picture, taking input sentences and converting them into token embedding + segment embedding + position embedding.
Outputs
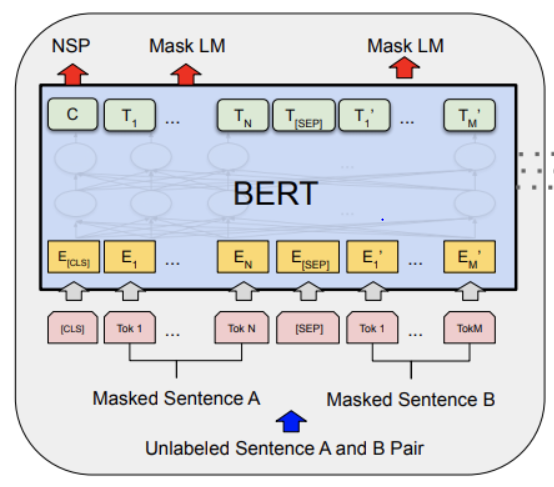
We have two types of outputs one is single token C and another one is T the whole sequence.
C is used for classification, trained during next sentence prediction. Classification task like spam detectors or sentimental analysis.
T is used for the word-level tasks.
Final Conclusion
To conclude we saw that a single word in one hot encoding inversion gets a smaller vector and from the smaller vector, we get several words that are often close to the initial words of the corpus. We saw word embedding with the skip-gram module. The tokenizer which we used is a WordPiece tokenizer
Saw working on the Attention Mechanism of RNN and its advantages and disadvantages.
Transformer-intuitions here we are taking whole sentences and not words and their composing sequences, and making different sequences and see how they are related to each other, it’s just a way to extract global information from the sentences.