
This post gives a brief overview of the complete NLP pipeline and the parts included in it.
The image below gives us an overview of the pipeline. The aim of any NLP project is to take in raw data, process and prepare it for modeling, run and evaluate models and finally make good use of the models so that it benefits us in some way.
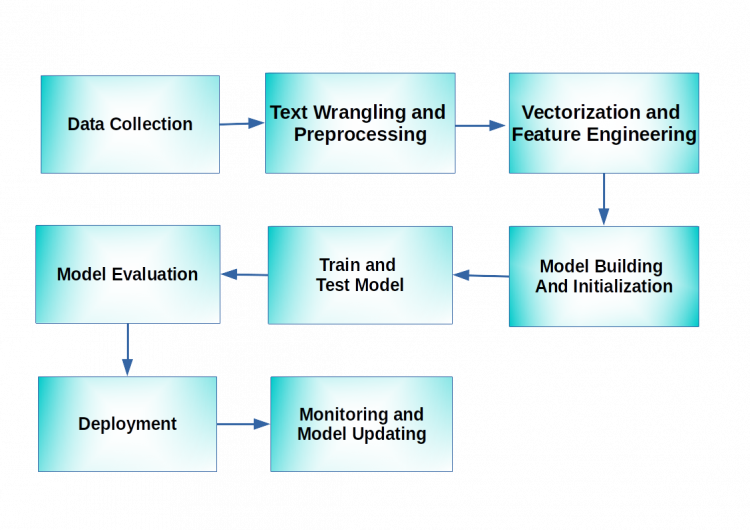
As can be seen in the above diagram, the pipeline consists of several different blocks. Let us try to focus on each block separately and understand how it contributes to the overall NLP process.
Data Collection –
The first step to solve any Machine Learning problem is to collect quality data. In NLP this data can be in the form of raw unstructured data.
The data we want can be scraped from websites or it may already be present in unstructured databases such as MongoDB, Cassandra, Redis, etc.
Data Wrangling and Text Preprocessing –
As mentioned previously, the data that we work with within NLP is mostly unstructured and raw.
Getting this unstructured data into a suitable format to carry out analysis is called Data Wrangling.
When I use the word “wrangle”, think of a cowboy wrangling with a bull. It’s a challenging task. In a similar sense, one has to wrangle with the “dirty” data to get into a “clean” format which would be suitable for further tasks.
The terms “Preprocessing” and “Data Wrangling” are sometimes used interchangeably.
The aim of this preprocessing step is to clean the messy data so that it is ready for further processing. In NLP, preprocessing consists of several steps as outlined below.
- Cleaning – This includes removing hashtags, HTML tags, URLs, etc.
- Normalization – This includes converting the text into lowercase, removing punctuation symbols and extra spaces.
- Tokenization – This includes splitting the normalized data into individual words or characters.
- Stop Word removal – Stop words include words that do not carry much meaning but are important grammatically. For example, words such as “to”, “is”, “but”, etc. can be counted as stop words. This step includes the removal of stop words.
- POS tagging – Parts-Of-Speech tagging is a step in which the “parts of speech” of the text data are identified.
- Named Entity Recognition – This includes labeling the “named entities” in the data such as names, places, etc.
- Stemming – Stemming includes converting words into their base/root form mostly by clipping off affixes like “er”, “y”, etc. For example, the words “computing” and “computer” can be converted to their base form i.e. “compute”.
- Lemmatization – Lemmatization too converts words to their base form but it doesn’t just clip words, it reduces them to their root word. For example, the word “studies” is converted to the root form “study”.
Please note that you may or may not utilize all of the above mentioned steps in your projects, as these steps can be modified based on your domain.
“Garbage in, garbage out” is a popular saying in ML which means your model will output whatever you feed it. Therefore it is extremely necessary to preprocess the data before feeding it to your model.
Vectorization and Feature Engineering –
In the introductory post, we had seen that in order for computers to understand human languages, the text has to be converted into numbers as it is easier for computers to work with numbers.
The process by which we convert text into numbers is known as vectorization. So basically, in this process, we are taking the text data and creating a vector of numbers. Think of vectors as a 1D array, like a NumPy array.
This is how computers make sense of text data. Vectorization is an important pillar of any NLP task. Without vectorization we won’t be able to apply any Machine Learning models on the text data.
There are different models to convert text data into vectors. Some are mentioned below :
- Bag-of-words model
- Tf-Idf model
- Word embeddings
Each of these methods will be explored in depth in the subsequent tutorials but for now let us get a brief intro to these methods.
The Bag-or-words model takes into consideration the frequency of the words in a corpus. A corpus is nothing but a set of documents. So a Bag-of-words model will just count how many times a word has been repeated in the corpus.
The TF-IDF (Term Frequency-Inverse Document Frequency) model takes into account not just the frequency of the words in a corpus but also the frequency of documents in which the word appears.
The Word embedding model will map the words into a vector space such that the words having similar meaning will be clustered together in the vector space.
If you feel overwhelmed right now, don’t fret, as we will be covering these topics in great detail in the subsequent tutorials.
Model building and Initialization –
In this step, you choose the ML model/models you will be running on the data. This may take into consideration the problem you are solving, the domain you are working in, etc.
Commonly used ML models for NLP tasks are Naive Bayes and SVM although other models can also be used.
Once you finalize the model, you can initialize it.
Training and Testing the model –
The next step after initializing the model is to begin training the model on the train data. The model will now learn all parameters from the train data.
Now, you test the model on a dataset that the model has not yet seen. This will help you to evaluate the performance of the model.
Model Evaluation –
As we saw in the previous point, testing the model on unseen data will help us to know if our model is overfitting, underfitting, or mapping the unseen data well.
Deployment –
After evaluating the model, you may either want to derive business insights with the help of the model or deploy the model i.e. put it into production so that it keeps running continuously to benefit your customers and your enterprise.
Monitoring and Model updating –
This step comes after you have deployed the model. After your model is running in production, you will want to keep track of how it is performing over time and update it when required so that it performs better and doesn’t start to malfunction.
This was an overview of the Natural Language Processing pipeline. We briefly touched upon a lot of different concepts and parts of the pipeline that contribute to the overall working of an NLP project. Thanks for reading.