
Natural Language Processing research and development is occurring concurrently in many languages. Some popular libraries in NLP are written in Python, Java, and C++. Lets us see why Python is the best of the lot for performing NLP tasks.
Python for NLP
Python is a high-level, general-purpose object-oriented programming language that has experienced a meteoric rise in popularity.
It is an open-source programming language, meaning that no one has to pay to download and use Python. It is absolutely free and ready to download and start using.
Moreover, Python’s syntax is simple and aids in code readability, ease of use in terms of debugging, and supports Python modules. Python encourages modularity and scalability.
Since Python is an extremely popular language in the developer community, if you get stuck on a piece of code, chances are someone else went through the same thing you are going through and would already have answered your query!
There are some amazing libraries in Python for NLP and almost all major development work in NLP is being done and shared in Python. This is one solid reason to use Python for NLP.
However, there is one drawback that is often attributed to Python and that is slower execution speed compared to compiled languages. An efficient way to overcome this problem is to use clever programming techniques and utilizing libraries built on compiles languages.
Keeping the above things in mind, we can start setting up our environment for NLP.
You may use any IDE of your choice to proceed further, but I would recommend using Google Colaboratory (colab) to make full use of the free GPUs.
Next, we will be going through a short guide on how to use and get started with Google Colab.
Getting to know Google Colab
If you have used Jupyter Notebooks before, you will find the Google Colab interface pretty similar to Jupyter Notebooks because Google Colab is a specialized version of the Jupyter Notebook that runs on the cloud and offers free computing resources.
You may ask “Why would anyone choose to use Google Colab? What’s the benefit?”
The answer is that Google provides you with free GPUs (Graphical Processing Units) and TPUs (Tensor Processing Units) as opposed to Jupyter Notebooks where you use your own local resources. This is beneficial when the hardware on your system isn’t strong enough.
There is a catch with using colab. The catch is that you can use the cloud resources only for a limited period of time in a day and if you overuse the resources, Google will suspend your access temporarily. Google does this so that the resources are not being overutilized by a single person.
You will need a functioning Google account to access Google Colab. So make sure of that before proceeding further.
The link to access Google Colaboratory is – https://research.google.com/colaboratory/
Once you click on the link, you will see a menu box where you can access your previously created notebooks or you can click on “New notebook” to create a new colab notebook.
Once you create a new notebook you will see a screen as shown in the image below.
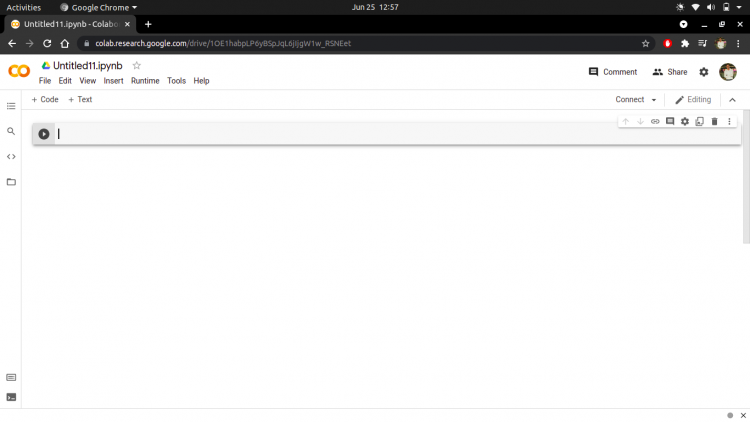
Make sure to give a name to your notebook so that you can find it easily later on.
To utilize GPus or TPUs click “Runtime” from the menu bar. Then select “Change runtime type”. From there, under the “Hardware accelerator ” you can select “GPU” or “TPU” based on your preferences.
Now, click the “Connect” button to access cloud resources. Once you are allocated resources, you will see a screen similar to the image shown below.
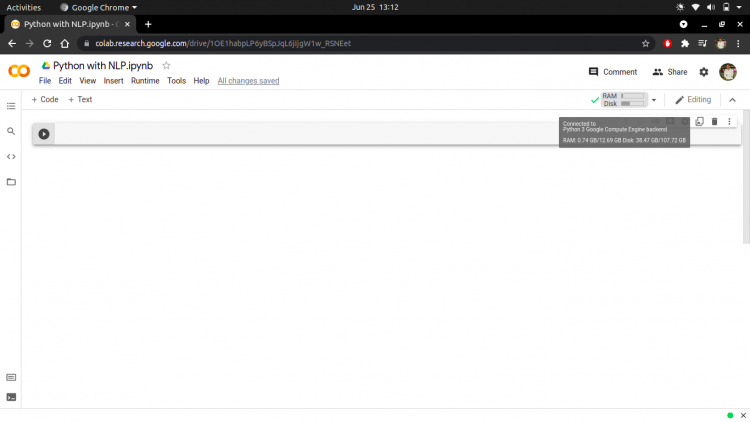
This means now you are ready to work.
Just like Jupyter Notebooks, Google Colab too saves and opens files in the “IPYNB” format. Keep in mind that since you are connected to a cloud instance, you cannot access local files from Colaboratory. But since this a Google service, you can access your Google Drive and load saved files from there.
Next, let us take a look at some of the most popular NLP libraries in Python
Prominent NLP libraries
Natural language Processing Toolkit (NLTK) –
Perhaps this library is the most popular one, and for a good reason. This is an excellent library to learn NLP.
Open a new notebook in colab or in your favourite IDE with Python 3x. Install NLTK if you haven’t done so already using the code snippet below.
You can install NLTK by typing the following code in the code block itself.
!pip install nltkNLTK allows us to access over 50 corpora and lexical resources. Now, let us play around with the library and see how we tokenize text in NLP. Note that we will be having a separate tutorial on tokenization, this is just to get you coding!
But wait! What is tokenization? Tokenizing a text document means splitting the text into a list of units. These units could be words, alphabets or sentences.
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenizeIn the above code snippet, we have imported the necessary libraries. We have imported NLTK and downloaded necessary data. Then we have imported our tokenizer i.e. word_tokenize.
text = "Who would have thought that computers would be analyzing human sentiments"
tokens = word_tokenize(text)
tokensHere, we have defined a sentence and assigned it to a variable “text”.
Next, we have initialized the tokenizer and given our text as an argument. Then we print the tokens.
tokens
['Who',
'would',
'have',
'thought',
'that',
'computers',
'would',
'be',
'analyzing',
'human',
'sentiments']As you can see, the sentence “Who would have thought that computers would be analyzing human sentiments” is tokenized. Here, the tokens are the individual words in our sentence. This tokenizer has split the sentence based on white spaces (” “).
Why do we perform tokenization?
If you remember, we had discussed in the previous articles that we have to convert text into mathematical objects for computers to understand them. Tokenization is the first step towards Vectorization. So, tokenization is an essential step in any NLP process.
Now that we have seen how to perform tokenization using the NLTK library, let us check the stop words available to us provided by this library.
import nltk
nltk.download('stopwords')
stopwords = nltk.corpus.stopwords.words("english")
stopwordsIn the above code snippet, we first import nltk and download the stopwords provided with the library.
Then, we assign the stopwords to a variable called “stopwords”. Finally, let’s check the output.
stopwords
['i',
'me',
'my',
'myself',
'we',
'our',
'ours',
'ourselves',
'you',
...The list of stop words is quite long. I have just included a few stop words due to spacing constraints. From the output, you get the idea that stop words are mostly connector words that do not carry much meaning in a sentence but are necessary to be grammatically correct.
Let us remove stop words from the text variable we defined earlier.
text = "Who would have thought that computers would be analyzing human sentiments"
text_cleaned = [x for x in tokens if x not in stopwords]
text_cleanedLet us check the output.
['Who',
'would',
'thought',
'computers',
'would',
'analyzing',
'human',
'sentiments']So why do we remove stop words?
We remove stop words because we do not want to increase the length of our vectors. We try to reduce it as much as we can because if the vectors of our texts are huge, the computational power and the time taken also increases.
We saw how to perform two essentials tasks i.e. Tokenization and Stop Word removal using the NLTK library. We will visit these topics in greater detail in the subsequent tutorials.
Other prominently used libraries
Textblob
Textblob is a library built on top of NLTK. It provides a very easy-to-use interface. This popular library is used for sentiment analysis, parts of speech tagging, translation, and so on. It is a good library for NLP beginners.
spaCy
spaCy is an advanced NLP library in Python. This library is written in Python and Cython (a language bridging the gap between Python and C), hence it has a faster execution speed compared to other libraries.
spaCy is used mostly in production environment. It can be used to build information extraction, or Natural language Understanding systems, or to preprocess text for deep learning.
VADER
Valence Aware Dictionary and sEntiment Reasoner (VADER) is another useful library specially used for the task of sentiment analysis. Sentiment analysis is the task where you try to predict the sentiment or emotions of the customers. The sentiment may be positive, negative, or neutral.
In this article, we saw why Python is a good choice for NLP, how to get started with Google Colab, and finally, we saw some popular NLP libraries. Thanks for reading, I’ll see you in the next one.