
Before diving into word embeddings we see the difference between syntax and semantics in NLP.
Syntax vs Semantics in NLP
We began our journey of converting text into words with the Bag of Words model and then we saw how to vectorize text using the TF-IDF method. One important thing to remember while using these methods is that they are syntactical methods or are based on the syntax of a language.
By syntactical methods, I mean that the BoW and TF-IDF methods only take into account the syntax of the text. The syntax of a language means the rules that define the language (grammatical rules) and it doesn’t take into account the meaning of the text. Think of a syntax error in Python when you miss a parenthesis.
In BoW and TF-IDF methods, we didn’t take into consideration what words came before certain words or what the meaning of the sentence or phrase was, we only took into consideration the syntax or grammatical structure of the language when vectorizing text.
Word embeddings are focused more on the semantics of the text. By semantics, I mean the meaning of the text, not just the grammatical structure. So why is taking semantics into account so important?
Taking semantics into account is important because semantics provide important information about the word in a sentence and it also provides information regarding its overall positioning and presence in a sentence. This information could not have been provided by using syntax alone. The surroundings or neighborhood of a word in a sentence provide semantic information.
So the semantics of a word is defined by the relationship of the word to its neighboring words and terms in a sentence. This is the idea on which the word embedding model is built.
Word embeddings
First of all, let me make it clear so that you don’t get confused. Word embeddings are a way to represent text in a mathematical format just like we did with BoW models and TF-IDF models. Word embedding models are a kind of vectorizer but they take into consideration the semantics rather than the syntax.
Word embedding is a learned representation of a word wherein each word is represented using a vector in n-dimensional space. This is a good definition of word embeddings. So, word embeddings are a kind of mathematical representation of our text where each word is represented by a vector. But what do we mean by n-dimensional space?
In mathematics, everything i.e. all calculations take place w.r.t. a dimension that we call a dimensional space. Think about our world, we live in a 3D world. Everything we touch and see is 3-dimensional. What about a line on paper? Well, a line is believed to be 2-dimensional. A point on paper is 1-dimensional.
Thus in mathematics, when we say n-dimensional we mean that there are n or that many features that the model has to work with. Suppose your data has 5 features, so you can think of your data being mapped to a 5-dimensional space mathematically.
Think about this, when you plot graphs in Matplotlib or any other software you are plotting 2-dimensional data. You can also plot 3-dimensional data using specialized software, but what about higher dimensions? Can you plot 6-D or 7-D plots using any software? No! Not yet! Because it gets difficult to visualize something as its dimensions increase but computers can work in higher dimensions with relative ease.
So word embeddings map the words in your text data to another dimension where words having similar meanings would have similar representations. This is a very important point to note. We will see some examples of this.
How do Word Embeddings capture semantics?
We saw that words with similar meanings should have similar representations. So for example, two words with different spellings that have the same meaning would be located close to each other in the n-dimensional space where n can take any value depending upon the feature size.
This would prove to be immensely helpful in finding synonyms (words with similar meanings), antonyms (words with opposite meanings), and various other relationships between words. The algorithm that helps us do this is called the Word2Vec algorithm which we will see in detail in the next tutorial. Here we just get a glimpse of it.
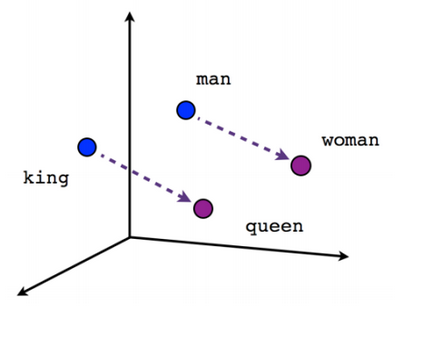
To understand the relationship between certain words we take an example. The example is of four words and they are King, Queen, Man, and Woman. If we take the word embeddings of these words we get the respective representations of these words. Now comes the interesting part.
Observe the relationship below
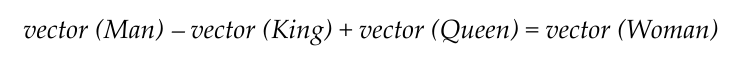
The relationship shows that if we take the word embedding representation of Man, add it to the representation of the word Queen, and subtract the representation of the word King then we get the representation of the word Woman. This is amazing!
This basically means that the below equation is true. We have just rearranged the terms from the above equation.
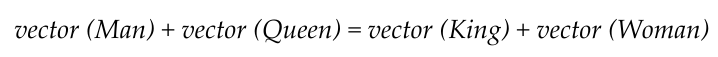
The words Man and King are closely related and so are the words Woman and Queen. We know this because a King denotes a Man and not a Woman. Similarly, when we use the word Queen, we know that she is a Woman. But the computer doesn’t know this.
With the help of word embeddings, however, the computer gets a hint that there is a kind of relationship between these words. In the n-dimensional space, the vectors of words King and Man are closer to each other and the words Queen and Woman are also closer to each other, as you can see in the image above. And thus these words are closely related.
This is how word embeddings capture semantics and helps the computer to understand the meaning between words and terms. This proves to be immensely helpful in NLP.
Getting to know the Word2Vec model
Just like we had seen in the case of the BoW model, the actual algorithm used to implement it was the CountVectorizer. Similarly, to implement word embedding we use an algorithm called the Word2Vec model.
The Word2Vec model as the name suggests converts words to vectors. So, the model will create vectors for words in a text. One point to note here is that Word2Vec differs from CountVectorizer and TF-IDF vectorizer because Word2Vec represents each word as a vector as opposed to the two other models where the whole document was represented as a matrix of vectors.
Another point to note is that we can use models which can convert sentences and even documents to vectors. As for now, we focus on words.
Here in this section, we just get a glimpse of the Word2Vec model and in the upcoming tutorials, we will explore this model in depth.
The Word2Vec model we will be using for demonstration purposes here is a model trained by Google on the Google News dataset. The vocabulary size of the model is a staggering 3 million words and phrases. The dimensions for each vector in this model are 300.
I suggest you use Google Colab for this task, but you are free to use any IDE you prefer.
We begin with the imports. We import Gensim which is a Python library and it allows us to work with this pre-trained model seamlessly.
import gensim
from gensim.models import KeyedVectors
import osWe now download the pre-trained Word2Vec model.
!wget -P /root/input/ -c "https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz"The output of the code above should be as follows.

As you can see the size of this model is 1.5 GB.
Since Colab runs in the cloud, we now change the directory to where we downloaded the model and load it. Follow the code snippet below.
os.chdir("/root/input")
!ls -al
model_path = '/root/input/GoogleNews-vectors-negative300.bin.gz'
model = KeyedVectors.load_word2vec_format(model_path, binary=True) Now we have loaded the model successfully. We now implement the relationship we had seen previously between the words Man, King, Queen, and Woman.
In the code snippet below, we add the representations of the words Man and Queen and subtract King. According to the formula we had seen above we should get the answer or most similar word as Woman. We also pass a parameter to show only the first most similar word.
result = model.most_similar(positive=['man', 'queen'], negative=['king'], topn=1)
print(result)The output is as follows.
[('woman', 0.7609435319900513)]The output shows how our model is correctly able to understand the relationship between the words. The model was able to find the mapping between these words and the closest resulting word in the higher dimensional space would be Woman. The second parameter in the result is the confidence that woman is the right output and it is correct as it is the most similar word.
Final Thoughts
In this article, we were introduced to the concept of word embedding. We first saw how it differs from other vectorization methods we have seen so far and how it finds relationships between words. We then used a pre-trained Word2Vec model to verify the working of word embedding models.
Thanks for reading.