Tokenization is the process of breaking down a text into smaller pieces. The tokenizing can be done at the document level to produce a token of sentences or doing sentence tokenizing and producing tokens.
Additionally, we can so do word tokenizing and extract characters from it. These tokens can be in any form words, punctuations, space, special characters, numbers, digits.
Tokenizing is the basic step to be performed for text processing pipeline or text mining, or text classification, etc.
Let’s take an example to see how tokenizing is done here we have taken the sentence “Hey Good morning!”
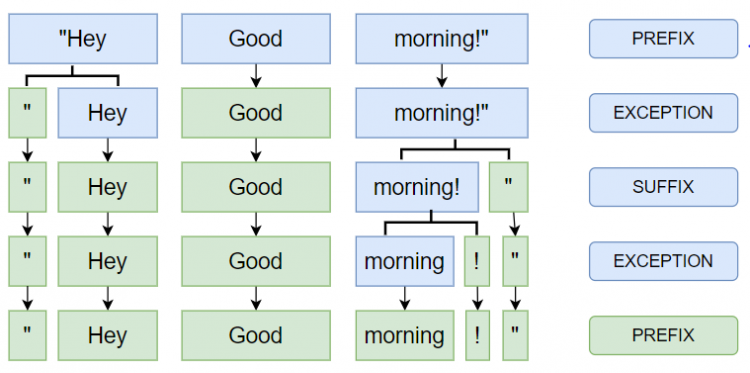
We saw how to tokenize the sentence when we have punctuations in the sentence. In spacy tokenizing of sentences into words is done from left to right.
The process of tokenizing
- First, the tokenizer split the text on whitespace.
- Then the tokenizer checks the substring matches the tokenizer exception rules or not. For exmaple, if sentences contain words like “can’t” the word does not contain any whitespace but can we decompose these words into two tokens. Yes, we can decompose into two words “can” and “n’t”.
- Now it will check puncuations in the string if it maches then it will split into two tokens.
Example 1
Load the spacy model to a variable nlp. Declaring the variable and downloading the model, spacy will take a couple of seconds to load the model. The load function of the spacy library is to load the model.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Hey Good morning!")
for token in doc:
print(token.text)
# Output
Hey
Good
morning
!Creating Tokenizer
In spacy, we can create our own tokenizer in the pipeline very easily. For example, we will add a blank tokenizer with just the English vocab.

Example 2
Here, we will see how to do tokenizing with a blank tokenizer with just English vocab. Importing the tokenizer and English language model into nlp variable. We will separate each token with a comma(,)
from spacy.tokenizer import Tokenizer
from spacy.lang.en import English
nlp = English()
# Creating a blank Tokenizer with just the English vocab
tokenizer = Tokenizer(nlp.vocab)
tokens = tokenizer("Hey Good morning! Let's go to school")
print("Blank tokenizer",end=" : ")
for token in tokens:
print(token,end=', ')
# Output
Blank tokenizer : Hey, Good, morning!, Let's, go, to, school, Example 3
Here, let’s see how the string will be tokenized using default settings for the English model.
from spacy.lang.en import English
nlp = English()
# Creating a Tokenizer with the default settings for English
tokenizer = nlp.tokenizer
tokens = tokenizer("Hey Good morning! Let's go to school")
print("\nDefault tokenizer",end=' : ')
for token in tokens:
print(token,end=', ')
# Output
Default tokenizer : Hey, Good, morning, !, Let, 's, go, to, school, If we see the difference in the default tokenizer and blank tokenizer we see how the “Let’s” word was not separated into let, ‘s in the blank tokenizer. We can create tokenizer rules based on our use cases.
Debugging the tokenizer
spacy provides a debugging tool as nlp.tokenizer.explain(text) which returns a list of tuples contains tokens and rules on which it was tokenized.
from spacy.lang.en import English
nlp = English()
text = "Hey Good morning! Let's go to school"
doc = nlp(text)
tok_exp = nlp.tokenizer.explain(text)
for t in tok_exp:
print(t[1], "\t", t[0])
# Output
Hey TOKEN
Good TOKEN
morning TOKEN
! SUFFIX
Let SPECIAL-1
's SPECIAL-2
go TOKEN
to TOKEN
school TOKENHere, as we see the token Hey, Let as a special-1 and ‘s as special-2.
Modifying existing rules of tokenizer
Spacy provides the modification of existing rules of tokenizer by adding or removing the characters from prefix, suffix, or infix rules with the help of NLP’s default object.
Adding characters in the suffixes search
In the below code, we will be adding ‘+’, ‘$’ to the suffix search rule so that whenever these characters are encountered in the suffix, could be removed. Loading the English model into a nlp variable. First, we will check how the normal tokenizer works.
from spacy.lang.en import English
import spacy
nlp = English()
text = "This is a+ tokenizing$ sentence."
doc = nlp(text)
print("Default tokenized text",end=' : ')
for token in doc:
print(token,end=', ')
# Output
Default tokenized text : This, is+, a-, tokenizing$, sentence. .,As we see in the above code special characters are not separated from the tokens. So now we will be declaring the rules for separating special characters from tokens. We will declaring if the sentences contain +, -, or $ then separated the token by adding this condition to nlp.Defaults.suffixes
suffixes = nlp.Defaults.suffixes + [r"\-|\+|\$",]
suffix_regex = spacy.util.compile_suffix_regex(suffixes)
nlp.tokenizer.suffix_search = suffix_regex.search
print('\nText after adding suffixes', end=' : ')
doc = nlp(text)
for token in doc:
print(token,end=', ')
# Output
Text after adding suffixes : This, is, +, a, -, tokenizing, $, sentence, .,Complete code.
from spacy.lang.en import English
import spacy
nlp = English()
text = "This is a+ tokenizing$ sentence."
doc = nlp(text)
print("Default tokenized text",end=' : ')
for token in doc:
print(token,end=', ')
suffixes = nlp.Defaults.suffixes + [r"\+|\$",]
suffix_regex = spacy.util.compile_suffix_regex(suffixes)
nlp.tokenizer.suffix_search = suffix_regex.search
print('\nText after adding suffixes', end=' : ')
doc = nlp(text)
for token in doc:
print(token,end=', ')
# Output
Default tokenized text : This, is+, a-, tokenizing$, sentence. .,
Text after adding suffixes : This, is, +, a, -, tokenizing, $, sentence, .,Adding a custom tokenizing class
We can customize the tokenizing class of nlp doc’s object. Here, we will see how to add a basic white space tokenizer to our tokenizer object. Loading the basic English model into nlp variable and passing white space tokenizer. we will create a class name WhitespaceTokenizer where we need to split the string on the basis of whitespace.
import spacy
from spacy.tokens import Doc
class WhitespaceTokenizer:
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = text.split(" ")
return Doc(self.vocab, words=words)
nlp = spacy.blank("en")
nlp.tokenizer = WhitespaceTokenizer(nlp.vocab)
doc = nlp("Hey, good morning!")
for token in doc:
print(token.text)
# Output
Hey,
good
morning!Sentnece Tokenizer
A sentence tokenizer is a process of splitting the text into sentences. Loading a spacy model into a variable nlp. We will use doc.sents to split the sentences from a paragraph.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is 1 sentence. This is 2 sentence.")
for sent in doc.sents:
print(sent.text)
# Output
This is 1 sentence.
This is 2 sentence.Final Conclusion
In this article, we saw what is tokenizing and how sentence tokenizer works and how to explicitly add the tokenizer rule as per the use cases.