
NER or Named Entity Recognition is an important part of Information Extraction in NLP. How do we define NER?
A formal definition of Named Entity Recognition (NER) is that it seeks to locate and classify named entities in text into predefined categories such as names of persons, organizations, locations, etc.
Let us start by understanding what a Named Entity means. A named entity means any real-world object. This may include names of persons (Jack, Jonas, etc.), locations (England, Chennai, etc.), organizations (Apple, Google, Microsoft, etc.). Basically, a Named Entity denotes anything that has a proper name.
Take the following sentence into consideration.
“To further elaborate on the geographical trends, North America had procured more than 50% of the global share in 2017 and has been leading the regional landscape of AI in the retail market.”
After processing we would want to know the named entities automatically tagged in the sentence as follows.
- North America – location
- More than 50% – percentage
- 2017 – date
- AI – Geological and Policital Entity
Now that we know what Named Entity in Named Entity Recognition means, let us look at what problem it tries to solve and how it benefits us.
Why perform NER?
The key aim to performing Named Entity Recognition on a piece of text is to extract key information from the text. When we extract key information from the text, it helps us to understand what the text is about.
In NLP, we work mainly with unstructured data.
By unstructured databases, I mean data that is not structured at all. For example, an excel spreadsheet can be thought of as a structured database with ordered rows and columns. But unstructured data like images, text, website information, videos, sounds are not always available in an orderly fashion.
So, when we work with unstructured data and we perform Named Entity Recognition on that data, we are essentially trying to convert that information into a more structured format because working with structured data is easier and convenient.
Apart from the above-mentioned reasons another thing to keep in mind is that the Named Entities contain more information about a text than most other words. And extracting these entities gives us more information about the text without worrying too much about the resultant vector size of the matrix that we feed to the model.
This is how NER benefits us primarily.
NER applications
Now that we know why performing NER is beneficial, let us look at some leading industry applications of this technique.
- Customer support – NER is used to categorize customer queries and requests to predefined classes so that it’s quicker and efficient to meet customer demands.
- Customer feedback – NER systems can help organize your customer feedback from various sources and will give you an insight of recurring problems. For example,
- Content recommendation – If you use Netlix or YouTube, you may have noticed how you are recommended videos or movies based on your favourite genres. NER majorly helps in this process of recommending you content by extracting information about how and what you like to watch.
- Process resumes – Every resume may contain the same basic details of a candidate but they differ in formatting, design and alignment. If a company gets a lot of resumes per day, then NER helps to parse through resumes swiftly and extracts the important information thus saving you a lot of time.
Performing NER practically
The main library we will be using for the sake of performing Named Entity Recognition here is spaCy. Although there are other ways and libraries to perform NER in NLP we will be focusing mainly on this library.
Using spaCy
spaCy’s Named Entity Recognition model has been trained on a corpus named “OntoNotes 5”. It gives pretty decent results.
First, let’s import the necessary libraries. On the first line, we are importing spaCy. Then we are importing displaCy to visualize the results. We next import a spaCy model and finally the pprint function.
Go through the following lines of code and run them.
import spacy
from spacy import displacy
import en_core_web_sm
from pprint import pprintIn the following block of code, we are first loading the imported model and initializing our spaCy engine. Actually both the lines perform the same action and you can choose any one of them.
nlp = en_core_web_sm.load()
nlp = spacy.load('en_core_web_sm')Next, let us take a sample text which has a diverse set of entities. As you can see, this text is rich in Named Entities and will help us check the performance of our model. Assign it to a variable called “text”.
text = """ Listen every weekday morning to an audio briefing from our hosts,
Shumita Basu and Duarte Geraldino. They’ll guide you through the most
fascinating stories in the news and how the world’s best journalists
are covering them. Apple News Today is free to everyone and is also
available in Apple Podcasts.
"""After defining the text, we pass the text to be processed by the spaCy model. This is done in the first line in the code below. After that, we print the Named Entities using the for loop in the last few lines of code.
If you remember from the previous tutorials, we had seen that when we pass a text to be processed by the spaCy model, it computes a lot of parameters and information about the text.
In our case, this information about our text is stored in the “entities” variable. Then looping over this data in “entities” and using “ent.text” and “ent.label” we print the corresponding text and the respective Named Entity.
entities = nlp(text)
print("Named entities in this text are\n")
for ent in entities.ents:
print(ent.text, ent.label_)Now, it’s time to observe the output and check for the Named Entities.
Output:
Named entities in this text are
weekday morning TIME
Shumita ORG
Duarte Geraldino PERSON
Apple News ORG
Today DATE
Apple ORGAs shown in the output above, we see that the model has actually done a great job at classifying the Named Entities. Let’s look at a few. If you look at our text, “Apple” is tagged correctly as an organization (ORG tag). “weekday morning” and “Today” are tagged correctly referring to the time (TIME) and date (DATE) respectively.
But the result is far from perfect. If you look at “Shumita”, the model has incorrectly classified it as an organization whereas she is actually a person. Apart from one mistake, the model did a pretty good job.
In the code snippet below, we are printing an important parameter along with the classified entity. We are printing the IOB tag. What’s that? IOB stands for Inside, Outside, and Beginning. It basically gives us the location of the word in the chunk. Run the following line of code.
pprint([(X, X.ent_iob_, X.ent_type_) for X in entities] )Let’s check the output.
Output:
[( , 'O', ''),
(Listen, 'O', ''),
(every, 'O', ''),
(weekday, 'B', 'TIME'),
(morning, 'I', 'TIME'),
(to, 'O', ''),
(an, 'O', ''),
...As you can see in the output, the tokens of our text along with two other parameters can be observed here. The first parameter is the token itself, the second parameter is the IOB tag and the third one is the Named Entity.
If we look at the third token here which is (every, 'O', '') we get the following information. The token is every, the IOB tag is ‘O’ specifying that this token is outside any other token i.e. not included in any other token and the last parameter says that no Named Entity recognized for this token.
If we look at the fourth token here which is (weekday, 'B', 'TIME') we get the following information. The token is weekday, the IOB tag is ‘B’ specifying that this token is the beginning of another token i.e. it is the beginning or first part of the token morning and the last parameter says that the Named Entity recognized for this token is TIME.
The token after the above-mentioned token is (morning, 'I', 'TIME') gives the same information as the above token with the exception that the tag here is “I” specifying that it is inside another token i.e. it is the second half or inside the token with the ‘B’ tag.
Finally, in the following code snippet, we visualize the results.
displacy.render(entities, style='ent', jupyter=True)After executing the above code in Colab or Jupyter notebook you will get an output that would be similar to the one given below.
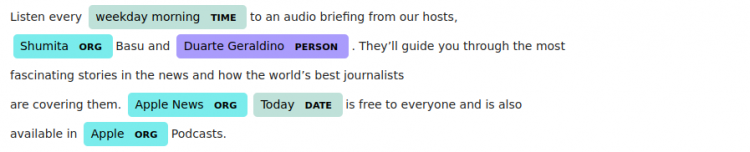
The shows a fancy way to visualize the output we got while processing with spaCy.
Final Thoughs
This concludes our tutorial on Named Entity Recognition. We first learned what is meant by NER, why it is useful in NLP, and how we can practically do it using the amazing spaCy library. Thanks for reading.