We will try to have a good call with the squad; which is the standard benchmark for the NLP. What is a squad? The squad is all about the question answering system. We will have a paragraph and we want our AI to find the answers to the questions from the paragraph.
For this example, we will use the TPU and not GPU. Clicking on the runtime and then selecting the TPU.
Step Import Dependencies
Importin the library with the pip command
!pip install sentencepiece
!pip install tf-models-official
!pip install tf-nightlyNow importing the library
import tensorflow as tf
import tensorflow_hub as hub
from official.nlp.bert.tokenization import FullTokenizer
from official.nlp.bert.input_pipeline import create_squad_dataset
from official.nlp.data.squad_lib import generate_tf_record_from_json_file
from official.nlp import optimization
from official.nlp.data.squad_lib import read_squad_examples
from official.nlp.data.squad_lib import FeatureWriter
from official.nlp.data.squad_lib import convert_examples_to_features
from official.nlp.data.squad_lib import write_predictions
import numpy as np
import math
import random
import time
import json
import collections
import os
from google.colab import driveAfter taking access to our drive folders and signing in to the drive folder.
Step Data Pre-Processing
drive.mount("/content/drive")
drive.mount("/content/drive")We will use the functions provided by google wrote for the processing. Now copy the path from your drive folder to here for train-v1 1.json and vocab.txt. Let’s create an train-v1 1.tf-record in the drive.
input_meta_data = generate_tf_record_from_json_file(
"/content/drive/MyDrive/Che-Cher-Tech/Squad/train-v1.1.json",
"/content/drive/MyDrive/Che-Cher-Tech/Squad/vocab.txt",
"/content/drive/MyDrive/Che-Cher-Tech/Squad/train-v1.1.tf_record")We will have access directly to the file and name the file as train_meta_data
with tf.io.gfile.GFile("/content/drive/MyDrive/Che-Cher-Tech/Squad/train_meta_data", "w") as writer:
writer.write(json.dumps(input_meta_data, indent=4) + "\n")Now we will create a dataset by calling the squad dataset and giving the size for batches.
BATCH_SIZE = 4
train_dataset = create_squad_dataset(
"/content/drive/MyDrive/Che-Cher-Tech/Squad/train-v1.1.tf_record",
input_meta_data['max_seq_length'],
BATCH_SIZE,
is_training=True)Step Model building
The first squad will be the beginning of the sentence and the second squad will be the end of the sentence. Our targets are two numbers; beginning and ending of answers. We will truncate the low and high values from the data. We can visualize the low and high values as in the bell-shaped chart.
class BertSquadLayer(tf.keras.layers.Layer):
def __init__(self):
super(BertSquadLayer, self).__init__()
self.final_dense = tf.keras.layers.Dense(
units=2,
kernel_initializer=tf.keras.initializers.TruncatedNormal(stddev=0.02))
def call(self, inputs):
logits = self.final_dense(inputs) # (batch_size, seq_len, 2)
logits = tf.transpose(logits, [2, 0, 1]) # (2, batch_size, seq_len)
unstacked_logits = tf.unstack(logits, axis=0) # [(batch_size, seq_len), (batch_size, seq_len)]
return unstacked_logits[0], unstacked_logits[1]Let’s now build a final model class. We will make a class BERTSquad where we will create a BERT layer and calling a light version of BERT. We will train the weights.
We will manipulate the inputs with the BERT and take the second output no the first output. The BERT layer has 3 inputs; word id, input mask, and input type id.
We will make a function call and it will return start and end logits means beginning and end of the sentences.
class BERTSquad(tf.keras.Model):
def __init__(self,
name="bert_squad"):
super(BERTSquad, self).__init__(name=name)
self.bert_layer = hub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1",
trainable=True)
self.squad_layer = BertSquadLayer()
def apply_bert(self, inputs):
_ , sequence_output = self.bert_layer([inputs["input_word_ids"],
inputs["input_mask"],
inputs["input_type_ids"]])
return sequence_output
def call(self, inputs):
seq_output = self.apply_bert(inputs)
start_logits, end_logits = self.squad_layer(seq_output)
return start_logits, end_logitsStep Training
Let’s set all the hyper-parameters for training the model. We won’t take all the data in batches.
TRAIN_DATA_SIZE = 88641
NB_BATCHES_TRAIN = 2000
BATCH_SIZE = 4
NB_EPOCHS = 3
INIT_LR = 5e-5
WARMUP_STEPS = int(NB_BATCHES_TRAIN * 0.1)Creating a lighter train dataset and calling the AI; BERTSquad.
train_dataset_light = train_dataset.take(NB_BATCHES_TRAIN)
bert_squad = BERTSquad()Now we will create an optimizer in which we will have a number of training steps and a number of warm steps.
optimizer = optimization.create_optimizer(
init_lr=INIT_LR,
num_train_steps=NB_BATCHES_TRAIN,
num_warmup_steps=WARMUP_STEPS)After completing with the optimizer we will create a loss function. We know the right position we need to have and we have the probability as output.
def squad_loss_fn(labels, model_outputs):
start_positions = labels['start_positions']
end_positions = labels['end_positions']
start_logits, end_logits = model_outputs
start_loss = tf.keras.backend.sparse_categorical_crossentropy(
start_positions, start_logits, from_logits=True)
end_loss = tf.keras.backend.sparse_categorical_crossentropy(
end_positions, end_logits, from_logits=True)
total_loss = (tf.reduce_mean(start_loss) + tf.reduce_mean(end_loss)) / 2
return total_loss
train_loss = tf.keras.metrics.Mean(name="train_loss")let’s see the training light dataset.
next(iter(train_dataset_light))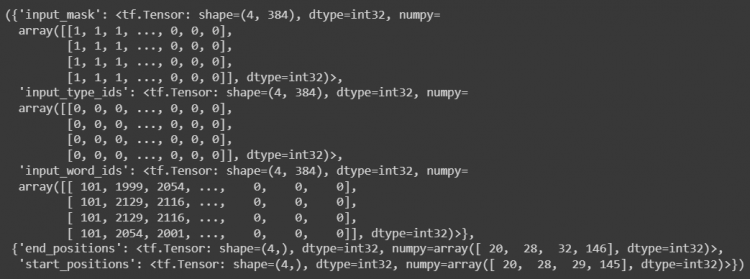
bert_squad.compile(optimizer,
squad_loss_fn)Let’s save the checkpoint in the drive for the bert model.
checkpoint_path = "./content/drive/MyDrive/Che-Cher-Tech/Squad/"
ckpt = tf.train.Checkpoint(bert_squad=bert_squad)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=1)
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print("Latest checkpoint restored!!")Custom Training
for epoch in range(NB_EPOCHS):
print("Start of epoch {}".format(epoch+1))
start = time.time()
train_loss.reset_states()
for (batch, (inputs, targets)) in enumerate(train_dataset_light):
with tf.GradientTape() as tape:
model_outputs = bert_squad(inputs)
loss = squad_loss_fn(targets, model_outputs)
gradients = tape.gradient(loss, bert_squad.trainable_variables)
optimizer.apply_gradients(zip(gradients, bert_squad.trainable_variables))
train_loss(loss)
if batch % 50 == 0:
print("Epoch {} Batch {} Loss {:.4f}".format(
epoch+1, batch, train_loss.result()))
if batch % 500 == 0:
ckpt_save_path = ckpt_manager.save()
print("Saving checkpoint for epoch {} at {}".format(epoch+1,
ckpt_save_path))
print("Time taken for 1 epoch: {} secs\n".format(time.time() - start))Getting the dev dataset in the session
eval_examples = read_squad_examples(
"/content/drive/MyDrive/projects/BERT/data/squad/dev-v1.1.json",
is_training=False,
version_2_with_negative=False)Defining the function for the dev dataset
eval_writer = FeatureWriter(
filename=os.path.join("/content/drive/MyDrive/projects/BERT/data/squad/",
"eval.tf_record"),
is_training=False)Creating a tokenizer for the further details
my_bert_layer = hub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1",
trainable=False)
vocab_file = my_bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = my_bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = FullTokenizer(vocab_file, do_lower_case)
def _append_feature(feature, is_padding):
if not is_padding:
eval_features.append(feature)
eval_writer.process_feature(feature)Creating the evaluation function
eval_features = []
dataset_size = convert_examples_to_features(
examples=eval_examples,
tokenizer=tokenizer,
max_seq_length=384,
doc_stride=128,
max_query_length=64,
is_training=False,
output_fn=_append_feature,
batch_size=4)
eval_writer.close()Loading the dataset for the session using
BATCH_SIZE = 4
eval_dataset = create_squad_dataset(
"/content/drive/MyDrive/projects/BERT/data/squad/eval.tf_record",
384,#input_meta_data['max_seq_length'],
BATCH_SIZE,
is_training=False)Making the prediction
RawResult = collections.namedtuple("RawResult",
["unique_id", "start_logits", "end_logits"])
def get_raw_results(predictions):
for unique_ids, start_logits, end_logits in zip(predictions['unique_ids'],
predictions['start_logits'],
predictions['end_logits']):
yield RawResult(
unique_id=unique_ids.numpy(),
start_logits=start_logits.numpy().tolist(),
end_logits=end_logits.numpy().tolist())
all_results = []
for count, inputs in enumerate(eval_dataset):
x, _ = inputs
unique_ids = x.pop("unique_ids")
start_logits, end_logits = bert_squad(x, training=False)
output_dict = dict(
unique_ids=unique_ids,
start_logits=start_logits,
end_logits=end_logits)
for result in get_raw_results(output_dict):
all_results.append(result)
if count % 100 == 0:
print("{}/{}".format(count, 2709))Now, writing the prediction in a json file that will work for the evaluation script
output_prediction_file = "/content/drive/MyDrive/projects/BERT/data/squad/predictions.json"
output_nbest_file = "/content/drive/MyDrive/projects/BERT/data/squad/nbest_predictions.json"
output_null_log_odds_file = "/content/drive/MyDrive/projects/BERT/data/squad/null_odds.json"
write_predictions(
eval_examples,
eval_features,
all_results,
20,
30,
True,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
verbose=False)