In the previous article, we got an overview of neural networks. If you haven’t read that article, I suggest you read the article on neural networks first so you understand the code easily. In this article, we will be building a question classifier.
A Question classifier
A question classifier is an algorithm that helps us classify the questions in a dataset according to its categories. For example, the questions in a dataset could be related to a range of topics such as humans, location, entity, numeric, etc.
Classifying these questions correctly can be immensely helpful when we are building advanced NLP applications that require the model to learn from a lot of question and answer datasets.
To build the classifier model we will be using an Artificial Neural Network. To build the neural network, we will be using a popular deep learning library called Keras.
The Keras library
Keras is a high-level deep learning framework that can be used to build neural networks. The Keras library is written in Python language. TensorFlow is another library that is very popular for deep learning purposes.
Earlier, Keras was used as a standalone library but now we can use it by importing TensorFlow. So with the help of these libraries, we will build the classifier today.
Building the classifier
The dataset that we will be using to build the classifier is the “question classification” dataset that is an open-source dataset. We will be trying to classify the questions in the data into six categories.
These categories are :
- ABBREVIATION
- ENTITY
- DESCRIPTION
- HUMAN
- LOCATION
- NUMERIC
You can find more information about the dataset at https://cogcomp.seas.upenn.edu/Data/QA/QC/
The data can be downloaded from: https://pythonwife.com/files/nlp/training_data.txt
https://pythonwife.com/files/nlp/test_dataset.txt
We begin with the imports. The libraries and modules we will be importing are given below.
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem.snowball import SnowballStemmer
from nltk.stem.wordnet import WordNetLemmatizer
import pandas as pd
import re
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelEncoder
import keras
from keras.models import Sequential, Model
from keras import layers
from keras.layers import Dense, Dropout, Input
from keras.utils import np_utils
import tensorflow as tfWe have imported quite a lot of libraries! We now load the dataset. We pass the location of the text files in our system. We open the text files in the read and write mode.
train_data = open('/content/drive/MyDrive/Datasets/training_data.txt', 'r+')
test_data = open('/content/drive/MyDrive/Datasets/test_dataset.txt', 'r+')If we print the data we see that it is a text wrapper.
train_data
# Output:
<_io.TextIOWrapper name='/content/drive/MyDrive/Datasets/training_data.txt' mode='r+' encoding='UTF-8'>To load the data in a way that we can work with, we will need to load it into a dataframe. For this, we will use the Pandas library.
train = pd.DataFrame(train_data.readlines(), columns = ['Question'])
test = pd.DataFrame(test_data.readlines(), columns = ['Question'])Now our data is loaded in the Pandas Dataframe object. We can now work with the data. Let’s print the top 10 rows of each dataframe to inspect the data.
train.head(10)Output:

We see that the dataframe consists of a question column. In each row, we see that the question class type is attached to the question. We will have to separate these first. Let’s also check the test dataframe.
test.head(10)Output:
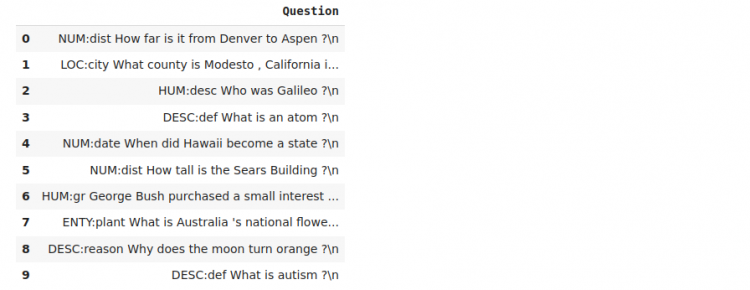
Here too, we see that the question type proceeds the actual question. We will have to separate these types from the questions.
Note that here we are already given the split data in train and test sets. So, we don’t have to later spilt the data ourselves. We split the data into train and test sets so that we can correctly measure the performance of our model. The model learns on the train set and predicts on the test set which it has not already seen.
We now want to separate the question class from the question as we had seen in the data. The data consists of questions and the type in a single sentence so we separate the two. In the code snippet below, we perform the separation of the question class.
In the first line, we create a new column and this column consists of the question class. For this, we use a lambda function. On the second line, we add to the existing column and it consists of the question corresponding to the question class.
On the third and fourth lines, we create two new columns with the general or coarse question type and the fine question type respectively. Once we look at the output, we will understand what these coarse and fine types mean. Basically, we are splitting the data to separate it and get what we want.
train['QType'] = train.Question.apply(lambda x: x.split(' ', 1)[0])
train['Question'] = train.Question.apply(lambda x: x.split(' ', 1)[1])
train['QType-Coarse'] = train.QType.apply(lambda x: x.split(':')[0])
train['QType-Fine'] = train.QType.apply(lambda x: x.split(':')[1])Now, we check the train dataframe.
train.head()Output:
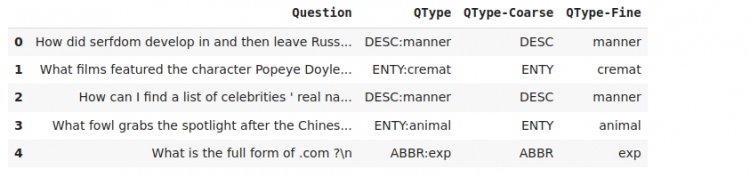
From the output, we see that three new columns have been added. All the questions are in the Question column. QType-Coarse contains the general six-question classes we had seen in the intro. QType-Fine column contains the finer subclasses within the general classes. QType contains both the general and fine types.
For our classifier, we will be using the coarse question type to train the model.
We apply the same transformations to the test dataframe that we had applied to the train dataframe.
test['QType'] = test.Question.apply(lambda x: x.split(' ', 1)[0])
test['Question'] = test.Question.apply(lambda x: x.split(' ', 1)[1])
test['QType-Coarse'] = test.QType.apply(lambda x: x.split(':')[0])
test['QType-Fine'] = test.QType.apply(lambda x: x.split(':')[1])We would observe the same output as we had for the train dataframe. We want to work with the general question classes and these are included in the QType-Coarse column. So we want to remove other columns and keep only the column we need i.e the QType-Coarse column.
In the code snippet below, we use the pop method to remove these columns from the train and test dataframes. You can also make use of the drop function.
train.pop('QType')
train.pop('QType-Fine')
test.pop('QType')
test.pop('QType-Fine')After removing the unwanted columns, we check the output.
train.head()Output:
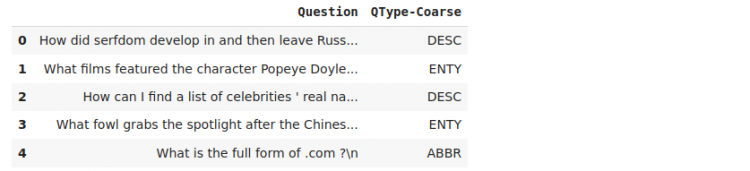
We see that we are left with the general question classes and the questions we had extracted before. Now the data is in the right format to work with.
We check the unique classes with the help of the code snippet below.
classes = np.unique(np.array(train['QType-Coarse']))
classes
# Output:
array(['ABBR', 'DESC', 'ENTY', 'HUM', 'LOC', 'NUM'], dtype=object)We see that our data has six different general classes for the questions. After training we want our model to accurately classify new questions into any of these six classes correctly.
We now want to convert our classes or labels into a numeric representation of integers. Since we have six classes here, we will get six classes as outputs. We use the label encoder to do this. In the code snippet below, we first instance a class of the encoder and then apply it to the QType-Coarse column which contains the labels.
First, we convert these columns to a list, add them, convert them to Pandas Series objects, take only their values and finally fit the encoder on these values.
le = LabelEncoder()
le.fit(pd.Series(train['QType-Coarse'].tolist() + test['QType-Coarse'].tolist()).values)Note that in the previous step, we have just fit the encoder to the data. We need to transform the data too. In the code snippet below, we apply the fitted encoder to the QType-Coarse columns of train and test and modify those columns.
train['QType-Coarse'] = le.transform(train['QType-Coarse'].values)
test['QType-Coarse'] = le.transform(test['QType-Coarse'].values)Now, we print the training dataset to see if the encoding was done correctly. We print the train set.
trainOutput:
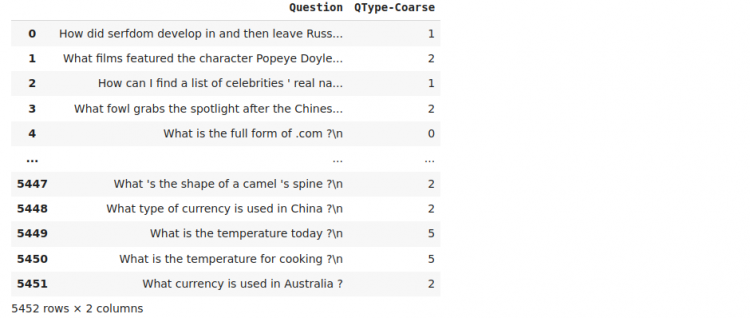
We see that in the column that contains our six-question labels, we now have encoded them to integers ranging from 1 to 6. Our model will predict any of these six integers after it is trained. Remember, we perform encoding because any Machine Learning model works only with numeric data.
Now, we want to want to do some preprocessing on our actual questions data columns. So, we take all the questions and combine them so that it is accessible through a single variable. In the code line below, we join the data from the Question columns and then convert it to the Pandas Series object.
all_corpus = pd.Series(train.Question.tolist() + test.Question.tolist()).astype(str)Let’s check out how the data looks.
all_corpus
# Output:
0 How did serfdom develop in and then leave Russ...
1 What films featured the character Popeye Doyle...
2 How can I find a list of celebrities ' real na...
3 What fowl grabs the spotlight after the Chines...
4 What is the full form of .com ?\n
...
5947 Who was the 22nd President of the US ?\n
5948 What is the money they use in Zambia ?\n
5949 How many feet in a mile ?\n
5950 What is the birthstone of October ?\n
5951 What is e-coli ?
Length: 5952, dtype: objectFor preprocessing, we will do two tasks. First, we’ll clean the data to keep only alphabets and remove punctuations. Then, we’ll remove stopwords. We use two functions for this purpose.
In the code snippet below, we define a function to perform general cleaning. Inside the function, we first initialize an empty Pandas Series. Then, we run a for loop and iterate over each row in the corpus. With the help of a nested for loop, we also iterate over each word of each row in the corpus.
We apply a regular expression pattern to each word in the row, and convert the word to lowercase. We store these words in a list and join them together.
def text_clean(corpus):
cleaned_corpus = pd.Series()
for row in corpus:
qs = []
for word in row.split():
p1 = re.sub(pattern='[^a-zA-Z]',repl=' ',string=word)
p1 = p1.lower()
qs.append(p1)
cleaned_corpus = cleaned_corpus.append(pd.Series(' '.join(qs)))
return cleaned_corpusIn the code snippet below, we define our second preprocessing function. This function helps to remove stopwords from the data. In the function, we keep some wh-words to preserve important information. We then load the stopwords provided by NTLK and filter them from our data.
def stopwords_removal(corpus):
wh_words = ['who', 'what', 'when', 'why', 'how', 'which', 'where', 'whom']
stop = set(stopwords.words('english'))
for word in wh_words:
stop.remove(word)
corpus = [[x for x in x.split() if x not in stop] for x in corpus]
return corpusAfter defining the function, we now call the functions on our corpus we had created previously which consisted of all questions. in the code snippet below, we apply the functions and join the data together to form our cleaned corpus called final_cleaned_corpus.
cleaned_corpus = text_clean(all_corpus)
stop_removed_corpus = stopwords_removal(cleaned_corpus)
final_cleaned_corpus = [' '.join(x) for x in stop_removed_corpus]The cleaned corpus will look like this.
final_cleaned_corpus[:10]
# Output:
['how serfdom develop leave russia',
'what films featured character popeye doyle',
'how find list celebrities real names',
'what fowl grabs spotlight chinese year monkey',
'what full form com',
'what contemptible scoundrel stole cork lunch',
'what team baseball st louis browns become',
'what oldest profession',
'what liver enzymes',
'name scar faced bounty hunter old west']We see that the data is now preprocessed and ready for further processing. We separate out the train and test sets we had joined previously.
train_corpus = all_corpus[0:train.shape[0]]
test_corpus = all_corpus[train.shape[0]:]To generate a mathematical representation of our text, we will convert the text into a TF-IDF representation. In the code snippet below, we instantiate a TF-IDF vectorizer and use the fit_transform method on our train set and transform method on the test set.
We do use fit_transform on the test set because we don’t want the model to learn the test data as it is unseen data to test the model. If we apply fit_transform to the test data, we will not get an accurate result of the model’s performance. Hence, we apply only transform to the test set.
vectorizer = TfidfVectorizer()
tf_idf_matrix_train = vectorizer.fit_transform(train_corpus)
tf_idf_matrix_test = vectorizer.transform(test_corpus)We now define a function to convert the sparse matrix that we received after applying the TF-IDF transformation to a tensor since we are working with the TensorFlow library. This function will take a sparse matrix and generate a sparse tensor.
def convert_sparse_matrix_to_sparse_tensor(X):
coo = X.tocoo()
indices = np.mat([coo.row, coo.col]).transpose()
return tf.sparse.reorder(tf.SparseTensor(indices, coo.data, coo.shape))We now call the function on the previously created TF-IDF representation.
x_train = convert_sparse_matrix_to_sparse_tensor(tf_idf_matrix_train)
x_train
# <tensorflow.python.framework.sparse_tensor.SparseTensor at 0x7f94b1545a50>As you can see in the output, we get a sparse tensor. TensorFlow works well with these tensors.
We apply the same to the test set.
x_test = convert_sparse_matrix_to_sparse_tensor(tf_idf_matrix_test)
x_test
# Output:
<tensorflow.python.framework.sparse_tensor.SparseTensor at 0x7eff335fd510>We now perform One-hot encoding. We take the QType-Coarse column which is already as integers and we one-hot encode them. One-hot encoding will basically create as many columns as there are unique values (here six since we used the nunique() method).
So, six columns will be created as our data has six unique classes and each column will correspond to the respective class. Whichever class the row label belonged to will now be encoded as 1 for that particular column in the row.
y_train = np_utils.to_categorical(train['QType-Coarse'], train['QType-Coarse'].nunique())
y_test = np_utils.to_categorical(test['QType-Coarse'], train['QType-Coarse'].nunique())
y_train
# Output:
array([[0., 1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
...,
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 1., 0., 0., 0.]], dtype=float32)As you can see in the output, we have six columns corresponding to the six general question classes. For whichever column 1 appears in the sparse matrix, it signifies that class label. For example, in the first row 1 appears for the second column, and hence the label is the second class.
We now build our ANN. In the code snippet below, we instantiate a sequential model because we are going to define a stack of layers. Then we add a dense layer which is a fully connected layer. We use the ReLU activation and we specify the input dimension.
Next, we add a dropout layer. It helps the model avoid overfitting. We then add another dense layer with softmax activation. This is also our last or output layer. We then compile the model with adam optimizer and a loss of categorical cross-entropy since we are doing classification.
We will test our model’s performance using categorical accuracy. We now check the summary of the model.
model = Sequential()
model.add(Dense(128, activation='relu', input_dim=tf_idf_matrix_train.shape[1]))
model.add(Dropout(0.3))
model.add(Dense(6, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['categorical_accuracy'])
model.summary()Output:
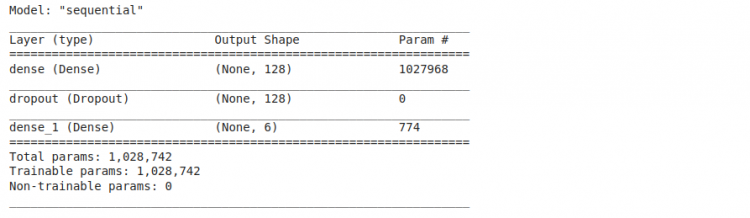
We can check the summary and see that there are approx 1 million parameters in such a simple network! We can also see the layers. We now train the model.
training_history = model.fit(x_train, y_train, epochs=10, batch_size=100)Output:

The model trains for 10 epochs or iterations. Now, let’s check the accuracy.
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
# Output:
Testing Accuracy: 0.8580We see that the ANN model has achieved a decent accuracy of 85% in classifying the questions according to their labels correctly.
The complete code used in the tutorial is given below for quick reference.
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem.snowball import SnowballStemmer
from nltk.stem.wordnet import WordNetLemmatizer
import pandas as pd
import re
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelEncoder
import keras
from keras.models import Sequential, Model
from keras import layers
from keras.layers import Dense, Dropout, Input
from keras.utils import np_utils
import tensorflow as tf
train_data = open('/content/drive/MyDrive/Datasets/training_data.txt', 'r+')
test_data = open('/content/drive/MyDrive/Datasets/test_dataset.txt', 'r+')
train = pd.DataFrame(train_data.readlines(), columns = ['Question'])
test = pd.DataFrame(test_data.readlines(), columns = ['Question'])
train.head(10)
test.head(10)
train['QType'] = train.Question.apply(lambda x: x.split(' ', 1)[0])
train['Question'] = train.Question.apply(lambda x: x.split(' ', 1)[1])
train['QType-Coarse'] = train.QType.apply(lambda x: x.split(':')[0])
train['QType-Fine'] = train.QType.apply(lambda x: x.split(':')[1])
test['QType'] = test.Question.apply(lambda x: x.split(' ', 1)[0])
test['Question'] = test.Question.apply(lambda x: x.split(' ', 1)[1])
test['QType-Coarse'] = test.QType.apply(lambda x: x.split(':')[0])
test['QType-Fine'] = test.QType.apply(lambda x: x.split(':')[1])
train.pop('QType')
train.pop('QType-Fine')
test.pop('QType')
test.pop('QType-Fine')
classes = np.unique(np.array(train['QType-Coarse']))
le = LabelEncoder()
le.fit(pd.Series(train['QType-Coarse'].tolist() + test['QType-Coarse'].tolist()).values)
train['QType-Coarse'] = le.transform(train['QType-Coarse'].values)
test['QType-Coarse'] = le.transform(test['QType-Coarse'].values)
all_corpus = pd.Series(train.Question.tolist() + test.Question.tolist()).astype(str)
def text_clean(corpus):
cleaned_corpus = pd.Series()
for row in corpus:
qs = []
for word in row.split():
p1 = re.sub(pattern='[^a-zA-Z]',repl=' ',string=word)
p1 = p1.lower()
qs.append(p1)
cleaned_corpus = cleaned_corpus.append(pd.Series(' '.join(qs)))
return cleaned_corpus
def stopwords_removal(corpus):
wh_words = ['who', 'what', 'when', 'why', 'how', 'which', 'where', 'whom']
stop = set(stopwords.words('english'))
for word in wh_words:
stop.remove(word)
corpus = [[x for x in x.split() if x not in stop] for x in corpus]
return corpus
cleaned_corpus = text_clean(all_corpus)
stop_removed_corpus = stopwords_removal(cleaned_corpus)
final_cleaned_corpus = [' '.join(x) for x in stop_removed_corpus]
final_cleaned_corpus[:10]
train_corpus = all_corpus[0:train.shape[0]]
test_corpus = all_corpus[train.shape[0]:]
vectorizer = TfidfVectorizer()
tf_idf_matrix_train = vectorizer.fit_transform(train_corpus)
tf_idf_matrix_test = vectorizer.transform(test_corpus)
def convert_sparse_matrix_to_sparse_tensor(X):
coo = X.tocoo()
indices = np.mat([coo.row, coo.col]).transpose()
return tf.sparse.reorder(tf.SparseTensor(indices, coo.data, coo.shape))
x_train = convert_sparse_matrix_to_sparse_tensor(tf_idf_matrix_train)
x_test = convert_sparse_matrix_to_sparse_tensor(tf_idf_matrix_test)
y_train = np_utils.to_categorical(train['QType-Coarse'], train['QType-Coarse'].nunique())
y_test = np_utils.to_categorical(test['QType-Coarse'], train['QType-Coarse'].nunique())
model = Sequential()
model.add(Dense(128, activation='relu', input_dim=tf_idf_matrix_train.shape[1]))
model.add(Dropout(0.3))
model.add(Dense(6, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['categorical_accuracy'])
model.summary()
training_history = model.fit(x_train, y_train, epochs=10, batch_size=100)
loss, accuracy = model.evaluate(x_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))Final Thoughts
In this tutorial, we have seen how to build a Question classifier using Artificial Neural Networks. Thanks for reading.