In the previous articles, we had seen the basics of Machine Learning and we had worked with certain algorithms for NLP. Now, we will explore deep learning which is a subset of machine learning that uses Neural Networks. So, in this article, we will explore Neural Networks.
Biological Neurons
Neural Networks are the building blocks of many deep learning techniques. But it would be better if we first understand the biology of these neural networks by looking at biological neurons that the neurons mimic.
A neuron is an electrically excitable cell that processes and transmits information through electrical and chemical signals. So, neurons are cells that communicate with each other using signals to pass on information. Neurons connect to form Neural Networks.
These neurons are a core component of the brain, spinal cord, and ganglia. These neurons send and receive signals that help humans to be able to respond to different stimuli, contract muscles, and carry on with their lives. So, essentially a neural network is made up of many many neurons.
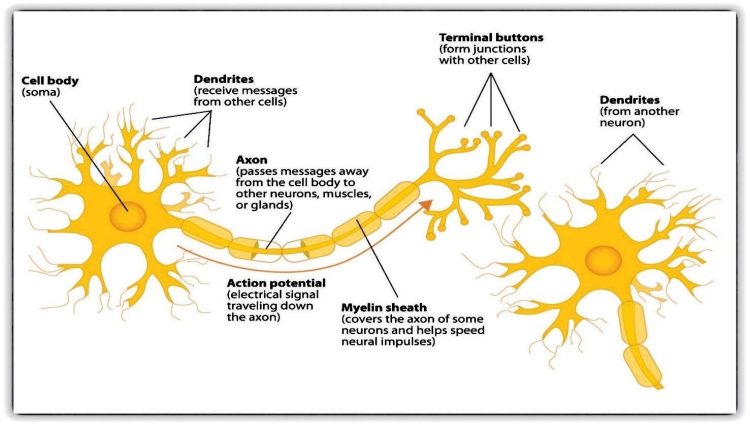
The image above shows the biological neurons found predominantly in the Central Nervous System. If you look at the structure of a neuron, it consists of a cell body, dendrites, axons, etc. The cell body hosts the mitochondria which is basically the powerhouse of the cell.
The dendrites in the cell help the cell to receive messages from other cells and axons help the cell to pass or transmit messages to other cells or parts of the body. Thus essentially the axons act as a transmitter and dendrites act as receivers for the cell. A synapse is what permits the cell to pass a signal to another cell.
In the image above you can also see how information is passed from one cell to another from axon to dendrite. But why are we discussing biology here? Because the idea of an Artificial Neural Network to solve complex problems was inspired by these natural neurons.
Artificial Neurons
In the previous section, we covered the biological neuron and the functions of its different parts. This is what inspired Artificial Neural Networks which are widely used in deep learning. We will look at how this network resembles the one found naturally.
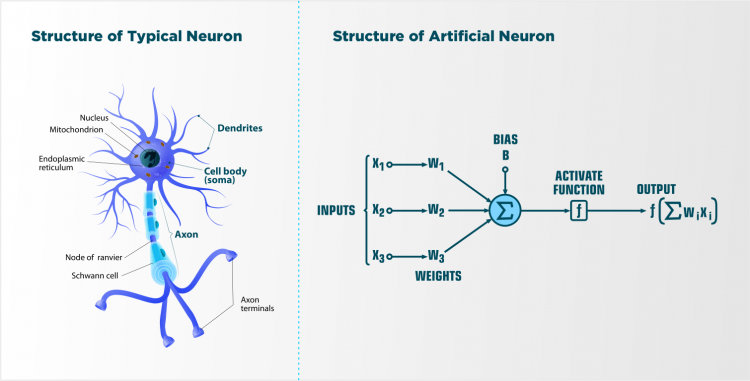
As you can see in the image above, a real neuron is compared to an artificial neuron. If we look at the real neuron on the left, we can identify its different parts i.e the dendrites, the axon, the nucleus, etc. So, for the artificial neuron on the left, we can find similarities too.
The artificial neurons have inputs, weights, bias, activation function, and output terms. The inputs are the features we feed the model with, weights are how the model learns. Bias is basically a summation function, then we have the activation function and finally the output.
Comparing it to the real neuron, we can see that the inputs are like the dendrites, the bias and activation function are like the nucleus and the output function is like the axon of the cell transmitting the signal. When a lot of such neurons are stacked and joined together, collectively it is called a neural network inspired by the network in the brain.
Basically, a neural network stimulates lots of interconnected brain cells inside a computer for the purpose of learning things, recognizing patterns, and making decisions in a human-like way. A mindblowing fact about neural networks is that it learns just like a human brain! No need to program it to work.
But remember, even though the neural network tries to imitate the behavior of an intelligent human brain, it itself is not a brain. It cannot think on its own. It is a software simulation. It is a very complex mathematical model that uses a lot of mathematical equations, unlike our brains.
Thus we looked at the similarities between a real neuron and an artificial neuron. The artificial neuron tries to mimic the behavior of a natural neuron to build a complex network called a neural network.
An Artificial Neural Network
An Artificial Neural Network is a network of artificial neurons. It could have artificial neurons in the range of hundreds to even millions of neurons.
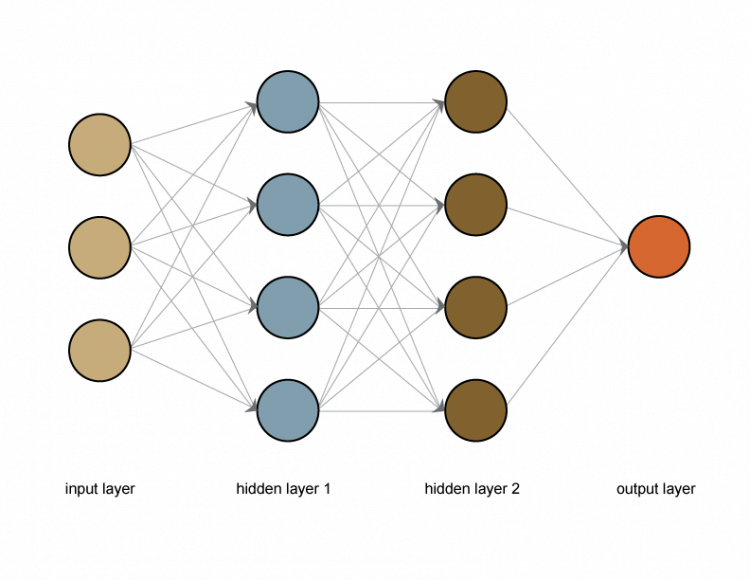
The image above shows a neural network. It is a simple network having only two hidden layers. In a neural network, artificial neurons are called units. And a collection of specific units in the network are called layers. In the image, we can see the input layer, hidden layers, and an output layer.
The input layer consists of units that help the network receive information from the outside world. This is the information that we want our model to learn. The output layer consists of units that help the model to respond in a certain way based on what it has learned.
The layers that sit between the input and output layers are called hidden layers. Hidden layers consist of units that help the model to learn the necessary information. We can choose how many hidden layers we want to have in our network. Lesser the layers, the simpler the network, and vice versa.
The image we see above is a fully connected network. What fully connected means is that all the units (artificial neurons) of a layer are connected to their succeeding layers. For example, if you look at the input layer which consists of three units, all three are connected to all the units in the next layer, and so on.
Just like biological neurons have synapses that help them communicate to other neurons, the artificial neural network has weights assigned between them. These weights help the network to know which units are prominent and therefore carry valuable information.
Working of a neuron in ANN
Now we focus on the computation part of an Artificial Neural Network. Before that, let us dive into the structure of an artificial neuron once again. The image below shows the structure of an artificial neuron.
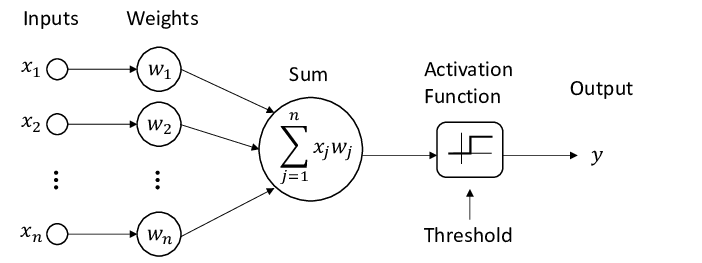
We have the inputs (x1, x2, …xn) which are the features of our data we want the network to observe and learn. So, first, we provide the inputs through the input layer. Note that here even though we are talking about one neuron, this explanation corresponds to the whole network as well because the network is composed of neurons.
After we pass the input, they are then multiplied with weights (w1, w2, … wn). These weights are helpful to the network to perform well. Think of these weights as the coefficients in a linear equation. These weights could be coefficients for lines or planes.
Take the equation of a line: ax + by + c
Here x and y are the inputs and a, b and c are the coefficients that are defined by the weights in the network. Thus for regression purposes, an optimal line can be drawn and for classification purposes, an optimal plane can be drawn that separates the classes effectively.
These inputs and weights are then summed using the summation function as shown in the figure. The summation function simply sums the inputs and their weights and passes them further to the activation function.
The activation functions
We saw that the summed output of the inputs and weights are now passed to the activation function. We’ll now see what an activation function does. The word activation in the name is actually due to how the biological neuron behaves.
The biological neuron becomes activate after a certain potential is reached and that threshold after which it activates is called the activation function. So, in neural networks, an activation function is defined as a function that reached saturation or max potential when it reaches a certain threshold.
The activation function basically decides whether a neuron should be activated or not.
Activation functions add nonlinearity to the network. Without an activation function, the network would just be like a linear regression model because till not the input is summed with the weights in a linear fashion. It is then passed to the activation function so that the model works with non-linear data as well.
The sigmoid activation function
The sigmoid activation function restricts the network output between a range of 0 and 1. So, when this activation function is used in the network, the output will always be between 0 and 1.
The formula for the sigmoid function is given as –
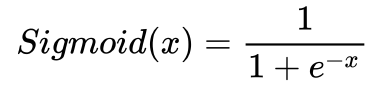
And the sigmoid curve looks like this –
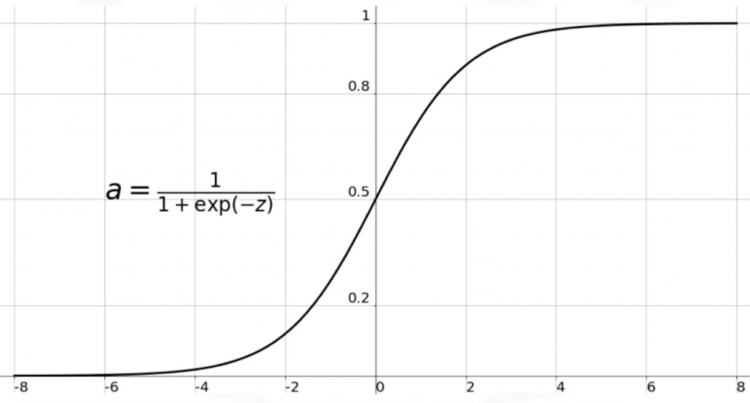
As you can see, the curve achieves saturation at 0 and 1. The function basically maps very large values to 1 and very small values to 0. This is helpful in binary classification problems where we have to deal with two classes only.
The Tanh activation function
The tanh activation function converts the inputs values between the range of -1 to 1. It is similar to the sigmoid function. The main difference between the sigmoid and tanh function is that tanh is a zero-centered function.
Zero centered means the function curve passes through the center. If you look at the sigmoid curve it doesn’t pass through zero.
The formula for the tanh activation function is given as –
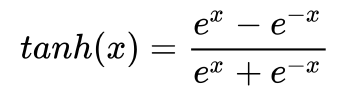
The curve for the tanh function is given below.
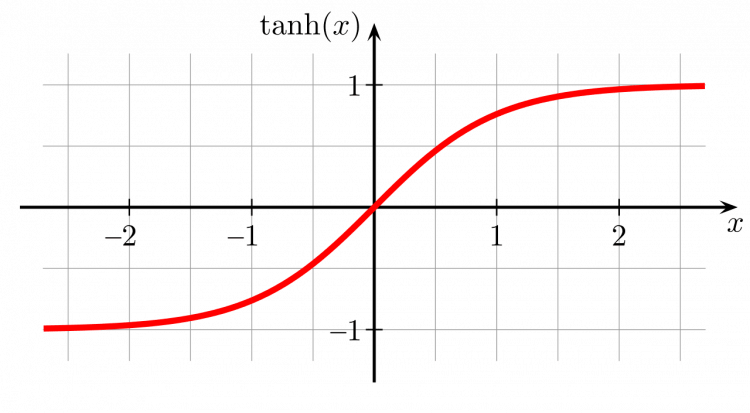
As you can see the curve passes through zero. The tanh function is used in many networks.
The ReLU activation function
ReLU stands for Rectified linear unit. This is the most commonly used activation function.
ReLU activation function can be defined using the formula –
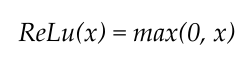
The graph for the ReLU function is given by
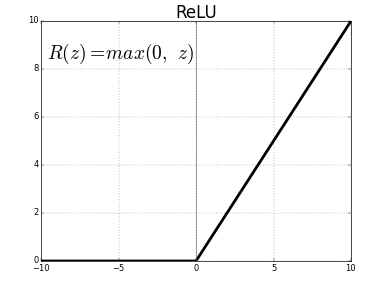
In ReLU, the threshold is set at 0. For values less than zero, the output is zero. As soon as the zero threshold is crossed, the output is then positive.
Before zero, i.e. for negative values, a neuron with ReLU would never get triggered. To overcome this problem a leaky ReLU can be used.
Leaky ReLU and ELU activation function
The leaky ReLU activation function overcomes the problem faced by the ReLU function. So, the problem faced by ReLU is that when the neurons are of negative values, they are not activated. This may not give optimum results as the neurons may never be fired.
Leaky ReLU overcomes this problem by modifying the ReLU function such that when the values are below zero, the output is not exactly zero but a small constant value. This can be seen in the graph for Leaky ReLU given below.

Due to the constant minimum value when the input is negative, this function is shown to perform better than the ReLU function in cases.
The ELU or Exponential Linear Unit gives the best of both worlds. It combines the advantages of ReLU and Leaky ReLU. It is shown in the graph below.

Final Thoughts
In this article, we have been introduced to the core concept of ANN which is the backbone of deep learning. We first looked at the biological neuron, then the artificial neuron, the neural network, and the working of neurons in the network.
By covering this article we are in a position to better understand advanced and complex deep learning models and techniques. Thanks for reading.