Neural Networks is a component of Artificial intelligence and is composed of artificial neuron and nodes that are meant to stimulate the functioning of a human brain. Using algorithms they can help classify the data or recognize the hidden patterns and correlation between them.
Different kinds of Neural Networks that are most popularly used are:-
- Convolutional Neural Networks ( CNN )
- Recurrent Neural Networks ( RNN )
- Autoencoders
- Generative Adversarial Networks ( GAN )
Neural Networks comprise nodes that are also called perceptrons take a set of input data and get trained input data to predict the output. Perceptrons are the mathematical model of biological neurons, just like electrical signals transferred between the neurons these signals are represented as numerical values. The obtained output result is fed to other perceptrons.
Perceptrons in Neural Networks
Machine Learning perceptron is an algorithm for supervised learning of binary classifiers. Perceptrons activate the cell based on the weights and input data. Single-layer perceptron consists of an input, sum function, activation function. Perceptrons apply weights on the input and sum all the inputs using the sum function and then evaluate using the activation function.
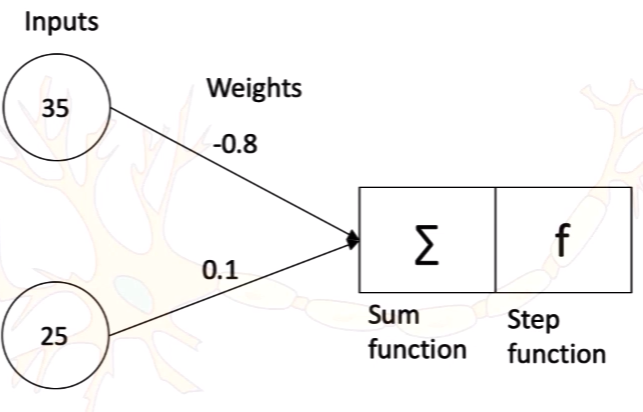
There are few points that determine the perceptron, they are
- Positive weight implies when applied over the input the chance of getting cell activated is more
- Negative Weight implies when applied over the input there is a chance of cell not getting activated
- Weights are considered as a Synapse as they get multiplied with input and result in a value that is either greater or less than the Threshold Value, which effects the cell to be activated or deactivated for communication.
- Weights applify or reduce the signal
- The Goal of the Neural Network is to learn for a best set of weights such that the prediction matches the Actual Value
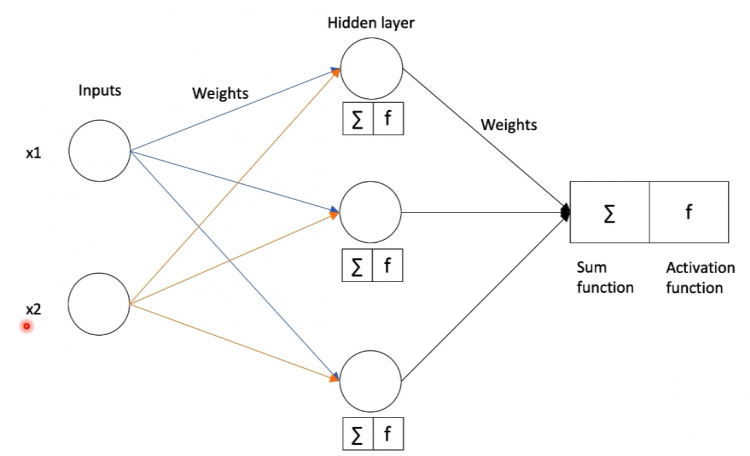
Multi-Layer Perceptron
A multi-layer perceptron is a combination of two or more hidden layers between input and output functions. Single-layer perceptron predictions are nearly accurate for linear or basic applications but when it comes to the commercial purpose the data is in the form of Non-Linear separable and requires multiple sum functions and activation functions.
Multi-Layer Perceptron is also called feed-forward neural network as the process moves from left to right as one layer feeds data into the next layer.
Error Calculation
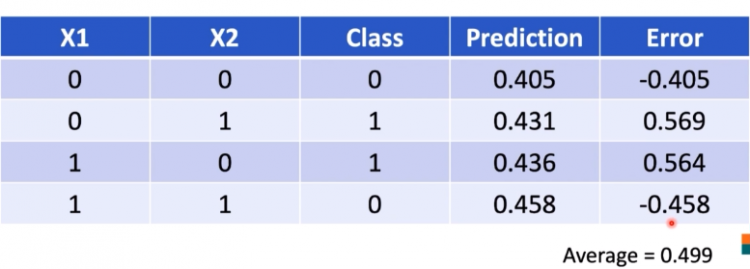
Loss Function is the most common term we use in neural networks. Error or Loss function predicts the loss of the model from a correct value. Error is calculated simply by subtracting the correct value and predicted value.
Error = Correct - PredictedIf we consider the below example we are performing an XOR operation on the outcomes of two inputs over different weights and we get the loss by subtracting the values of the prediction form class. To minimize the loss we can calculate the average of all the predictions and then accordingly apply weights to reduce loss.
Gradient Descent and Derivative
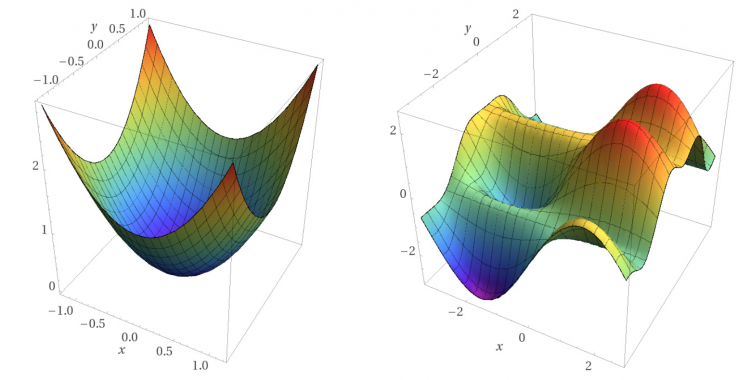
Gradient Descent is a first-order iterative optimization machine learning algorithm that detects the slope in all directions and automatically adjusts the parameters( weights ) of the equation to obtain minimum loss such that predicted values are not nearly close to other actual values.
It applies derivation for each possible weight to obtain slope, direction and plot a graph to check for the local minimum and global minimum. Using these global minimum and local minimum it predicts in which direction the weights have to be adjusted(either increase or decrease) to obtain minimum loss functions.
Local Minimum is a point where the function achieves a minimum value for a particular range and there is a chance of obtaining a better minimum value for other values of the range.
Global Minimum is a point where function gives the most feasible solution for all the values provided as input, in gradient descent, we obtain the global minimum for every weight.
Delta Calculation
Delta is an important parameter for determining gradient. It determines whether the weight has to be reduced to left or right for reducing the error function.
Delta = error * sigmoid derivative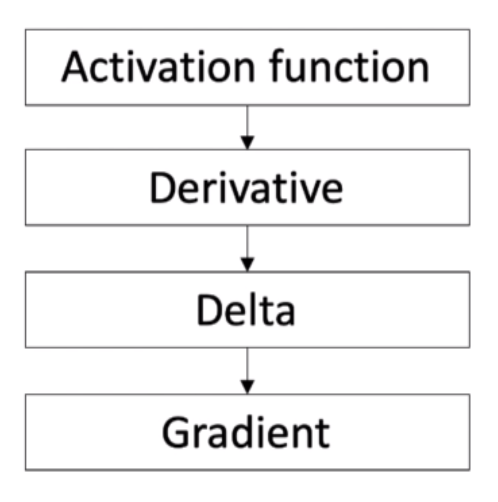
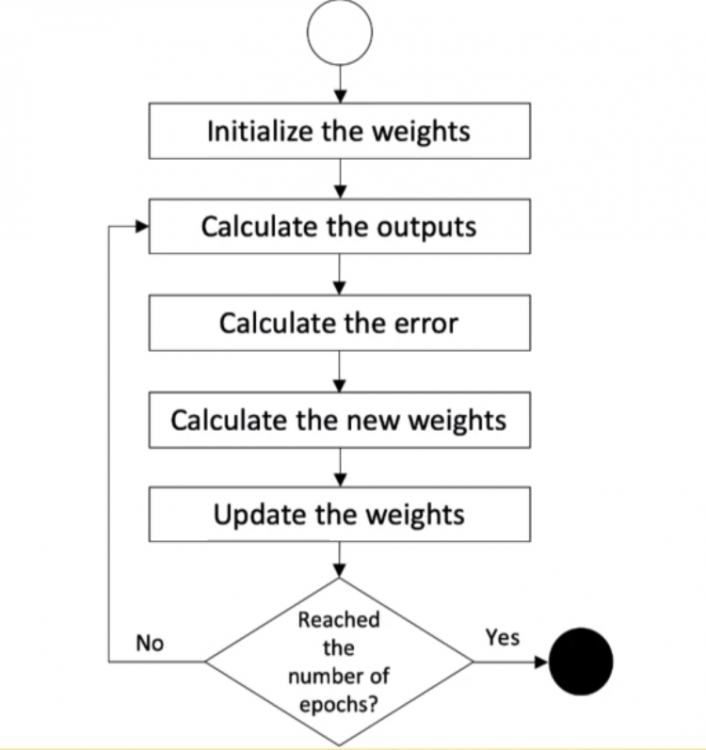
Weight Update using Backpropagation
Weight Update implies adjusting the weights to reduce the loss function and this task is performed from right to left in the reverse direction. Thus backpropagation is applied for updating the weight.
weight(n) = weight(n-1) + (input * delta * learning_rate)Every model has its learning rate and it has its own characteristics. The learning rate is a tuning parameter for weight update that determines the step size for each iteration. It determines how fast the model is.
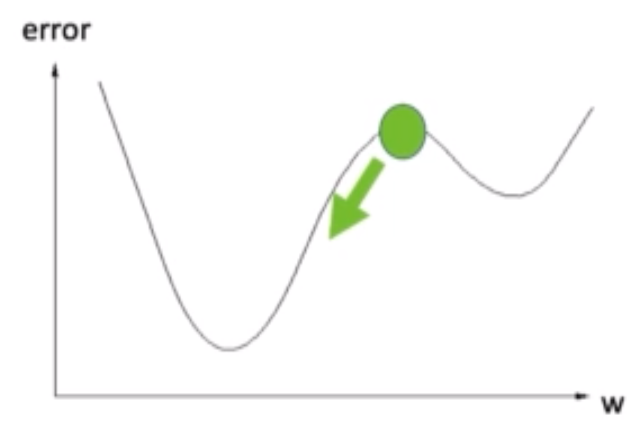
In the below figure, the weight update is moving from local minimum to global minimum. If the learning rate is high the model is fast and may cross the global minimum because of the speed and if the learning rate is low, the model is slow but reaches the global minimum much precisely.
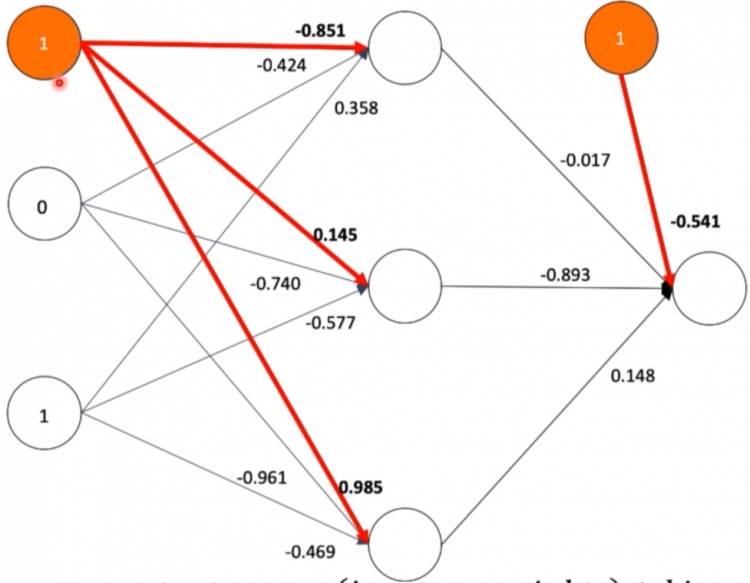
Bias
Bias act as additional neurons in the network but does not represent an activation function. Bias help moves the output of the activation function to either left or right so that the local minimum is overcome to meet the global minimum of the function.
As we can see the orange color circles are the bias that is connected to the nodes to help change the output of the respective node. By default, every machine learning model will be having its own bias.
Output = (input*weight) + Bias