
Let us start by defining what Part-of-Speech tagging means.
We saw that part-of-speech or POS tagging is necessary for Lemmatization. It is important for other NLP tasks and problems as well. So, what is POS tagging?
POS tagging or part-of-speech tagging may be defined as the process of assigning a part of speech to the given word.
It may sound confusing at first and so to make things easy to understand we first have to revisit our high school grammar. We first have to be familiar with the parts of speech.
If you recall your high-school grammar, you may remember that any sentence is made up of several grammatical components. These may include nouns, verbs, adverbs, adjectives, pronouns, conjunction as so on.
To give a quick refresher, I have listed a very basic definition of the important parts of speech with some examples.
- Noun – represents a thing and these things may include a person, place, animal, idea, etc. Examples include bottle, Jaipur, tiger, etc.
- Verb – represents an action. Examples include clean, hoping, working, etc.
- Adjective – represents the qualities or states of nouns. Examples include big, small, clean, etc.
- Adverb – represents and describes a verb. Examples include now, peacefully, carefully, etc.
- Pronoun – Substitutes for a noun or noun phrase. Examples include he, she, they, etc.
- Conjunction – Joins together sentences, phrases, words, etc. Examples include when, unless, so that, etc.
Note that this is very basic definition and I have not listed all the grammatical parts.
Okay, so now we know what the parts-of-speech are. Now what does this “tagging” in “POS tagging” mean?
To tag, something means you classify it as something. When you visit websites to read articles or blogs, you must have noticed that those articles or blogs are tagged with specific topics. Thus tagging is a kind of classification.
So basically in POS tagging, we are taking the individual words and automatically tagging them with their correct part-of-speech. This the main function or role of a POS tagger.
The parts of speech explains how a word is used in a sentence.
A tagset is called a set of predefined tags. This is essential information that the tagger must be given. Rather than using our own tagset, we usually make use of well-known defined tagsets.
Relevance of POS tagging in NLP
Now that we have a better understanding of what a POS tagger does, the question that arises is “what is the relevance of POS tagging in NLP?” or “what’s the use of tagging words with their parts-of-speech?”.
It is very important to note that POS tagging just like tokenization is an important and essential preprocessing part of an NLP pipeline. In fact, before tagging words, we have to tokenize them. Only after tokenizing we move ahead with POS tagging.
A lot of NLP applications, tasks, and methodologies depend on POS tagging. Some of these tasks include information retrieval, information extraction, text-to-speech systems, named entity recognition, question-answering, etc.
If the POS taggers don’t provide good accuracy then other downstream (advanced) tasks may suffer. Therefore it is necessary that we design a good POS tagger.
Now that we have seen what POS tagging is and why it is important, let’s implement it practically.
POS tagging with Python
We have several options when it comes to tagging text using Python. Let us look at some libraries that can be used to implement POS tagging.
Please open a new Colab notebook or your preferred IDE so that you may follow along as we code.
1. Using NLTK
The NLTK library is one of the most popular libraries for NLP and for a good reason. As it turns out, we can use NLTK for the task of POS tagging too. Let’s see how.
First we import the NLTK library.
Next, we define a sentence and assign it to the variable “txt”. On the third line, we are converting our text to lowercase. This helps to reduce the size of our vector.
On the fourth line, we are tokenizing our text into words and finally printing the tokenized words.
import nltk
txt = ("We are trying to learn how pos tagging works")
txt = txt.lower()
words = nltk.word_tokenize(txt)
wordsThe output of the above code is as follows.
Output:
['we', 'are', 'trying', 'to', 'learn', 'how', 'pos', 'tagging', 'works']As I had mentioned previously, before POS tagging the words it is necessary that we tokenize our text first.
Now, we use the POS tagger provided by NLTK to POS tag our words. We also print the POS tags. Use the following code.
pos_tags = nltk.pos_tag(words)
pos_tagsThe output that we get is as follows.
Output:
[('we', 'PRP'),
('are', 'VBP'),
('trying', 'VBG'),
('to', 'TO'),
('learn', 'VB'),
('how', 'WRB'),
('pos', 'JJ'),
('tagging', 'NN'),
('works', 'NNS')]As you can see in the output, the words in our input sentence are tagged automatically to their respective parts of speech. If you look at the parts-of-speech tags you may get confused by what does “PRP” means or what does “JJ” means. Let’s how we can access the tagset.
The following block of code helps us to decipher the tags provided by NLTK.
import nltk
nltk.download('tagsets')
print(nltk.help.upenn_tagset())After running the above code, we get the output.
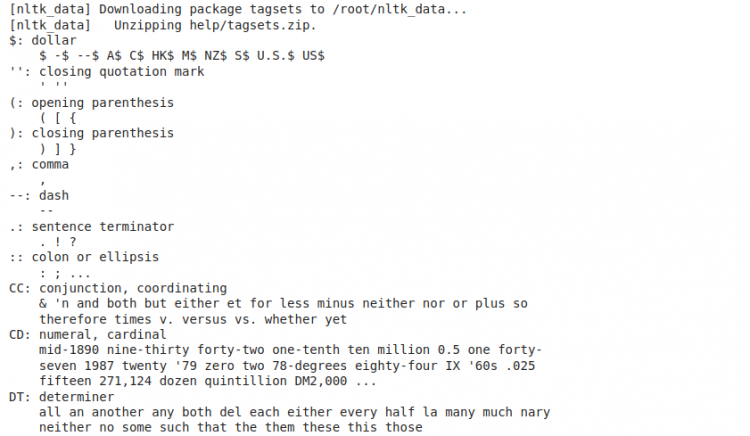
We get a complete list of what the abbreviations mean. For example, in our POS tag code, “PRP” stands for Pronoun and “JJ” stands for Adjective.
Now we have seen how we can tags words using NLTK. Let’s move on to the next library.
2. Using TextBlob
The TextBlob library as we know is built on top of the NLTK library. It provides additional functionality and ease of use. Let’s see how to tag words.
POS tagging using TextBlob is really simple.
First, we import the library as shown in the first line. Next, we define a text sentence and assign it to the variable called “txt”.
In the third line, we output the automatically generated tags.
from textblob import TextBlob
txt = TextBlob("Python is a high-level, general-purpose programming language.")
txt.tagsOne thing to note here is that the TextBlob library takes care of tokenizing the text. We don’t have to explicitly tokenize the text as in NLTK.
Now, let’s look at the output.
[('Python', 'NNP'),
('is', 'VBZ'),
('a', 'DT'),
('high-level', 'JJ'),
('general-purpose', 'JJ'),
('programming', 'NN'),
('language', 'NN')]The output shows that our code works as the words are tokenized and are tagged to their respective parts of speech.
Since this library uses NLTK as its base, the same tagset gives us a reference as it did in the NLTK code section. You can refer to that tagset to decipher the tags.
Let’s use spaCy to see how we can tag pats-of-speech.
3. Using spaCy
spaCy is an advanced library. Therefore we can get much more information about our text than we did with the other two libraries. Let’s see how.
In the following lines of code, we are first importing the spaCy library. On the next line, we are loading and initializing a spaCy model. SpaCy provides several models and for our task, “en_core_web_sm” will do just fine.
import spacy
nlp = spacy.load('en_core_web_sm')After initializing, we define the sentence and pass it as an argument to the spaCy model.
Whenever you pass any text to the spaCy model, it does a lot of work at the backend to preprocess the text. What I meant to say in the previous sentence will be clear after observing the output of the following code.
After passing the text to the model, we run a for loop and print out the following information about each token:
- the token
- the lemmatized token
- the POS tag
- the token tag
txt = nlp(u'Natural Language Processing is a part of Artificial Intelligence')
for token in txt:
print(token.text, token.lemma_, token.pos_, token.tag_)After running the above code, it’s time to check the output.
Output:
Natural Natural PROPN NNP
Language Language PROPN NNP
Processing Processing PROPN NNP
is be AUX VBZ
a a DET DT
part part NOUN NN
of of ADP IN
Artificial artificial ADJ JJ
Intelligence Intelligence PROPN NNPAs you can observe in the output, the text has automatically been tokenized by the spaCy model. Apart from that, there is much information about each token.
Let’s take the fourth token into consideration. The token is “is” and it has been properly lemmatized as “be” which is the lemma of “is”. It also says that it is an auxiliary verb and has been tagged correctly.
From the output we see that spaCy does a fantastic job at POS tagging and preprocessing text without much code.
Final thoughts
In this article, we saw what POS tagging is, we also learned the importance of POS tagging. After that, we implemented POS tagging using 3 different libraries.
Thank you for reading.